








서 론
한국은 노인 인구의 비중이 급속히 증가하는 대표적인 국가로 노인 돌봄의 수요 또한 급속히 증가하고 있다[1]. 특히, 2017년도 노인실태조사에 따르면, 전체 노인들의 가구 수 중 노인독거가구와 노인부부가구의 비율이 약 80%에 달하고 있어 노인 돌봄은 가장 중요한 사회적 문 제 중 하나로 떠올랐다[2,3]. 복합적 욕구를 갖고 있는 노인 인구의 다양한 문제를 해결하기 위해 국내에서는 2020년부터 노인의 복합적인 욕구를 통합적이고 포괄적으로 파악하고 체계적으로 자원을 연계하는 새로운 사례관리기반 서비스인 노인맞춤돌봄서비스를 도입하였다[4]. 그러나 통합사례관리 및 자원 연계 과정에서 발생하는 현장 사례관리자들의 반복적인 업무에 대한 부담, 이중 기록, 경력과 역량에 따른 조사의 정확성 및 연계 자원의 적절성의 상이함 등이 지적되어왔다. 특히, 코로나19 기간 동안 대면 중심의 방문상담이 제한되어 지역사회 노인들의 돌봄 욕구를 파악하는 데 어려움을 겪고 있어 새로운 접근법 모색이 요구되고 있다[5]. 해외에서는 이러한 어려움들을 극복하기 위해 사회복지 분야 대규모 데이터베이스들을 통합하여 분석하는 빅데이터 기반의 접근 방식이 고려되었고 여러 연구에서 그 유용성을 확인하였으나[6-10] 국내에서는 통합사례관리를 위한 빅데이터 기반 연구가 미비한 실정이다[2].
이에 본 연구에서는 우리나라 노인 돌봄과 관련된 세 가지 사업인[11] 한국사회보장정보원의 통합사례관리 빅데이터(행복 e음; 통합사례관리 자료), 노인돌봄서비스, 지역사회통합돌봄 선도사업에서 수집된 자료를 최초로 연결하여 구축한 통합데이터를 활용해 국내 지역사회 노인의 돌봄 욕구와 이와 연계되는 자원을 예측하는 기계학습 기반의 모형을 구성하고 검증하고자 하였다. 먼저 통합사례관리는 지역사회 자원에 대한 체계적인 관리 지원 체계를 토대로 대상자에게 필요한 서비스를 통합적으로 연계하여 제공하며 지속적으로 상담 모니터링하는 사업으로, 해당 데이터셋은 여러 복합적인 욕구를 가진 대상의 발굴 및 초기 상담, 욕구 조사 및 대상자 선정, 그리고 서비스 제공결정 및 모니터링 과정에서 수집된 데이터로 구성되어 있다. 노인돌봄서비스 사업은 돌봄의 사회화 욕구가 높아짐에 따라 이에 대응하기 위해 추진된 정책 사업으로, 해당 데이터셋은 2019년 지자체별 수행기관에서 독거노인을 대상으로 안부확인 및 자원연계를 제공하면서 수집한 독거노인현황조사 자료와 2020년 기존 6개의 노인돌봄사업이 노인맞춤돌봄서비스로 통합 개편되면서 대상자 선정을 위해 수집한 자료로 구성되었다. 마지막으로 지역사회통합돌봄 선도사업은 돌봄이 필요한 주민이 살던 곳에서 개개인의 욕구에 맞는 서비스를 누리고 지역사회에서 살아갈 수 있도록 주거, 보건의료, 요양 등 여러 가지 사회서비스를 통합적으로 지원하기 위해 시행된 정책 사업으로, 해당 데이터셋은 선별평가도구와 심화평가도구로 수집된 자료로 구성되었다. 본 연구에서는 이렇게 각 사업별로 개별적으로 조사된 데이터들을 여러 방식으로 연결한 통합 데이터를 구축하여 분석했을 때 기계학습 모형을 적합한 결과(예측 성능)를 비교함으로써 빅데이터 기반의 접근 방법이 실제 지역사회 노인의 욕구-자원 간 연계 패턴 분석에 유용한 지에 대한 실증연구를 진행하고자 한다.
본 연구의 2장에서는 분석에 사용할 데이터들을 결합한 방식과 통합데이터의 변수에 대해 설명한 뒤 기계학습 기반의 분석 모형인 다중 레이블 분류 기법을 소개하고, 3장에서 분석 결과와 예측 모형의 해석을 위해 변수 중요도 결과를 설명하며, 4장에서 본 연구의 의의와 한계점들을 고찰하고자 한다.
연구 방법
자료원 및 변수 설명
본 연구에서는 한국사회보장정보원의 통합사례관리 빅데이터(행복 e음) 2019-2020년 자료를 기본으로 하여 지자체에서 조사된 노인돌봄서비스 자료 및 지역사회통합돌봄 자료를 공통 ID 변수를 통해 연결하여 결합한 세 종류의 통합데이터를 구축하였다. 구축된 통합데이터는 통합사례관리 자료의 욕구 및 문제영역과 자원 대분류 및 중분류 관련 변수들을 반응변수로, 통합사례관리 자료의 기초상담, 인적정보, 욕구 및 문제영역 변수들과 노인돌봄서비스 및 지역사회통합돌봄 자료의 변수들을 설명변수로 구성하였다.
최초 통합사례관리 자료는 돌봄 대상자의 돌봄 욕구를 파악할 수 있는 10개 욕구와 20개 문제영역 변수 그리고 지역사회의 돌봄 자원을 분류한 9개의 자원 대분류와 하위의 51개 자원 중분류 변수가 존재하였다. 본 연구에서 검토한 18개의 반응변수는 (1) 욕구 영역-일상생활 유지, 경제, 건강, 생활환경 4개 변수, (2) 문제영역-주거 내부 환경 개선, 신체 건강 유지, 의식주 관련 일상생활 유지, 기초생활 해결 4개 변수, (3) 자원 대분류-신체 건강 및 보건의료, 일상생활, 보호 및 돌봄 요양, 정신 건강 및 심리 정서, 주거 5개 변수, (4) 자원 중분류-식사 식품 지원, 생활용품 지원, 정서발달 및 치유 지원, 질병 예방 및 건강 관리, 주거환경 개선 5개 변수였다.
설명변수로는 (1) 통합사례관리 자료의 상담유형, 상담결과 판정의견, 가구유형, 주거환경, 주거상태, 주거유형, 가옥구조, 난방방법으로 구성된 기초상담 및 인적정보에 해당하는 변수 86개의 변수를 본 분석에 활용하였다. (2) 노인돌봄서비스 자료는 2019년 독거노인현황조사 자료와 2020년 노인맞춤돌봄서비스 대상자 선정 자료를 연계하여 두 자료에서 공통으로 제공되는 신체활동, 가족관계, 생활 여건, 신체기능, 사회적 관계, 신체, 정신 항목에서 조사·수집된 138개 변수를 통합데이터의 설명변수로 사용하였다. (3) 지역사회통합돌봄 자료는 선별평가도구와 심화평가도구 두 도구로 조사된 노쇠평가, 돌봄욕구, 건강영양, 인지기능, 정신건강, 생활지원 항목의 변수 79개를 설명변수로 사용하였다.
본 연구에서는 익명화 처리된 공통 ID를 이용하여 통합사례관리 자료와 노인돌봄서비스 자료를 결합한 통합데이터인 ‘데이터 (A)’, 통합사례관리 자료와 지역사회통합돌봄 자료를 결합한 통합데이터 ‘데이터 (B)’, 그리고 통합사례관리 자료와 노인돌봄서비스 자료와 지역사회통합돌봄 자료를 결합한 통합데이터 ‘데이터 (C)’를 구축하고 활용하였다. ‘데이터 (A)’는 분석 대상자 15,434명에 대해 욕구 및 문제영역을 반응변수로 볼 경우 176개의 설명변수를 가지며 자원(대분류, 중분류)을 반응변수로 볼 경우 욕구 및 문제영역의 변수를 포함해 총 208개의 설명변수를 가진다. ‘데이터 (B)’는 분석 대상자는 4,075명에 대해 욕구 및 문제영역은 334개의 설명변수, 자원(대분류, 중분류)은 365개 설명변수를 가진다. 마지막으로, ‘데이터 (C)’의 분석 대상자 600명에 대해 욕구 및 문제영역의 설명변수는 412개, 자원(대분류, 중분류)의 설명변수는 419개로 구성되었다. 각 통합데이터에서 자원(대분류, 중분류) 항목 분석 시 설명변수의 개수가 각각 다른 이유는 자료 구축 시 공통 ID를 가진 분석 대상자로 자료가 줄어들면서 한 개의 값만 갖게 되는 특정 변수들을 분석에서 제외하였기 때문이다.
분석 모형
본 연구의 중요한 특징은 분석 대상자들이 반응변수를 복수 선택할 수 있다는 점이었다. 예를 들어, 욕구 영역 레이블에서 개인이 선택할 수 있는 반응변수 레이블은 {일상생활 유지, 경제, 건강, 생활환경}으로, 네 가지 레이블 중 하나만 선택하는 것이 아닌 여러 개의 레이블을 동시에 선택할 수 있도록 조사가 이루어졌다. 이러한 유형의 데이터를 분석하는 방식 중 먼저 다중 클래스 분류(Multi-class classification)를 살펴보려고 한다. 다중 클래스 분류법은 위의 네 가지 레이블로 만들 수 있는 모든 조합을 우선 고려한다. 해당하는 집합은 {욕구 없음, 일상생활 유지, 경제, 건강, 생활환경, (일상생활 유지, 경제), (일상생활 유지, 건강), (일상생활 유지, 생활환경), (경제, 건강), (경제, 생활환경), (건강, 생활환경), (일상생활 유지, 경제, 건강), (일상생활 유지, 경제, 생활환경), (일상생활 유지, 건강, 생활환경), (경제, 건강, 생활환경), (일상생활 유지, 경제, 건강, 생활환경)}으로 16가지 경우로 구성된다. 개별 노인의 대답은 위의 16가지 중 정확히 하나에 대응될 수 있다. 이처럼 다중 레이블 문제를 1개의 조합만 선택 가능하도록 한 후 분석하는 방법을 다중 클래스 분류라고 한다. 그런데, 다중 클래스 분류 문제는 일반적으로 K개의 레이블이 존재하는 경우 2 K개의 가능한 조합이 생기게 되고, 이를 예측하는 모형을 만들어야 한다. 가능한 조합의 숫자가 K에 따라 매우 빠르게 증가하기 때문에, 적절한 K값을 갖는 경우에도 일부 클래스 내에서는 관측치 수가 매우 적거나 존재하지 않는 상황이 빈번하게 발생하여 분석의 어려움이 생길 수 있다. 또한 계산량이 빠르게 증가하는 문제도 발생한다.
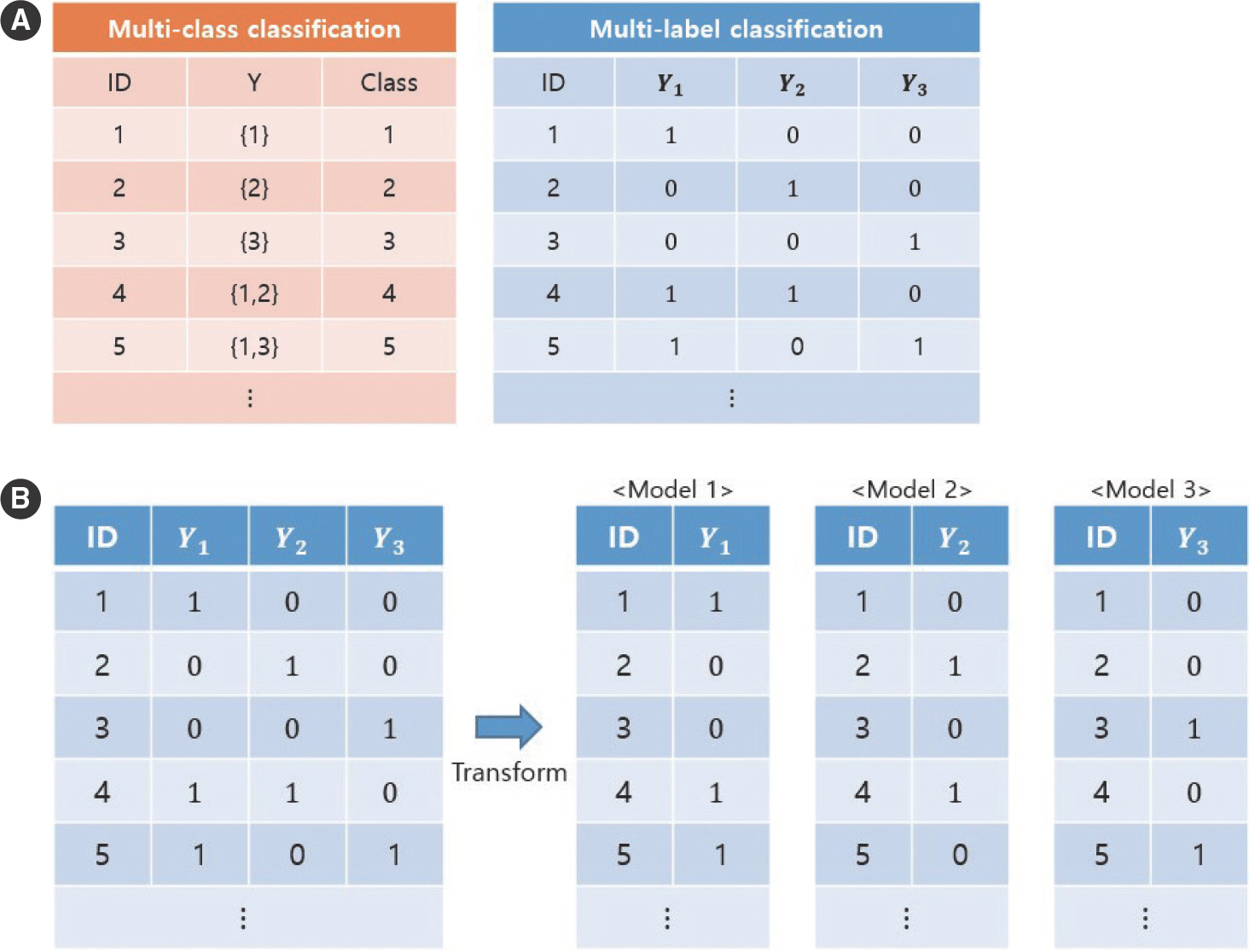
이러한 어려움을 피하기 위해, 본 연구에서는 우리는 각각의 레이블을 이항 변수로 표현된 벡터 형태로 이해하는 방식의 다중 레이블 분류(Multi-label classification)를 이용하여 분석을 진행하였다. 다중 클래스 분류와 다중 레이블 분류의 자료 구조의 차이는 Figure 1A를 통해 확인할 수 있다. 예를 들어, ID가 5인 대상자의 경우 Y1과 Y3에 대한 욕구가 있는 경우에 해당하면 {1,3}으로 표시되는데. 이는 5번째 조합(Class=5)이 된다. 이와 달리 다중 레이블 분류에서는 오른쪽 표와 같이 Y1과 Y3에서는 1로 욕구가 있음을, Y2에서는 0으로 해당 욕구가 없었음을 나타낸다.
Figure 1.
Description of multi-class classification and multi-label classification representing label variables. (A) Multi-classification vs. Multi-label classification. (B) Description of Binary relevance to divide multi-labels into multiple binary forms.
본 연구에서는 다중 레이블 분류 문제를 해결하기 위해 문제 변환방식 중 널리 사용되고 있는 이진형 분류(Binary relevance)와 앙상블 체인 분류기(Ensemble classifier chain, ECC) 2가지 방식을 적용하였다[12]. 먼저, 이진형 분류는 개별 레이블마다 독립적인 이진 분류 모형을 학습시키는 방식으로 K개의 레이블이 존재하면 K개의 모형을 개별로 학습하는 방식으로 다중 레이블 분류 문제를 접근한다[13,14] (Figure 1B). 이진형 분류는 단순하게 문제 변환을 통해 레이블들을 분류할 수 있다는 장점이 있지만, 레이블 간의 연관성이 존재하는 경우 이를 반영하지 못한다는 단점이 존재한다. 그러나, 연관성을 반영하지 못한다는 점이 항상 단점이 되는 것은 아니며, 레이블들 간의 조합이 불규칙한 경우에 예측 모형이 과적합(Over-fitting) 되는 것을 방지하는 장점이 있는 것으로 알려져 있다[15].
다중 레이블 분류 방법을 다루는 다른 방식의 앙상블 체인 분류기를 설명하기 전에, 그 기반이 되는 체인 분류기를 먼저 소개하겠다. 체인 분류기는 이진형 분류처럼 여러 개의 레이블을 이진 분류 문제로 변환하는 방식은 유지하되 레이블 간의 연관성을 반영하기 위해 고안되었다. 이 알고리즘은 각 레이블을 랜덤한 순서로 1개씩 이진 분류 모형을 적합 하는데, 이때 얻은 레이블의 예측 값을 다음 차례의 레이블을 예측할 때 설명변수로 추가하는 방식으로 적합을 진행한다. Figure 2를 통해 살펴보면 Step 1에서 랜덤하게 뽑힌 첫번째 레이블(Y1)을 비복원추출하고, Step 2에서 추출된 레이블을 기존 설명변수들(X)을 통해 예측 모형을 적합하여 예측 값()을 구한다. Step 3에서는 Step 1에서 선택되지 않은 레이블들 중 랜덤하게 뽑힌 두번째 레이블(Y2)을 같은 방식으로 비복원추출하고, Step 4에서는 Step 2에서 구해진 을 설명변수에 추가하여 예측 값()을 구한다는 것을 확인할 수 있다. Step 5에서는 모든 레이블의 예측 값이 구해질 때까지 Step 3와 Step 4를 반복한다. 이 알고리즘은 레이블 간의 연관성을 반영하기에는 적절하지만, 레이블이 뽑히는 순서에 의해 예측 값이 달라질 수 있는 위험을 지니고 있다. 이를 극복하기 위해 체인 분류기를 여러 번 적합한 예측 결과들을 다수결을 통해 합치는 방식의 알고리즘이 추가된 앙상블 체인 분류기가 고안되었다[10].
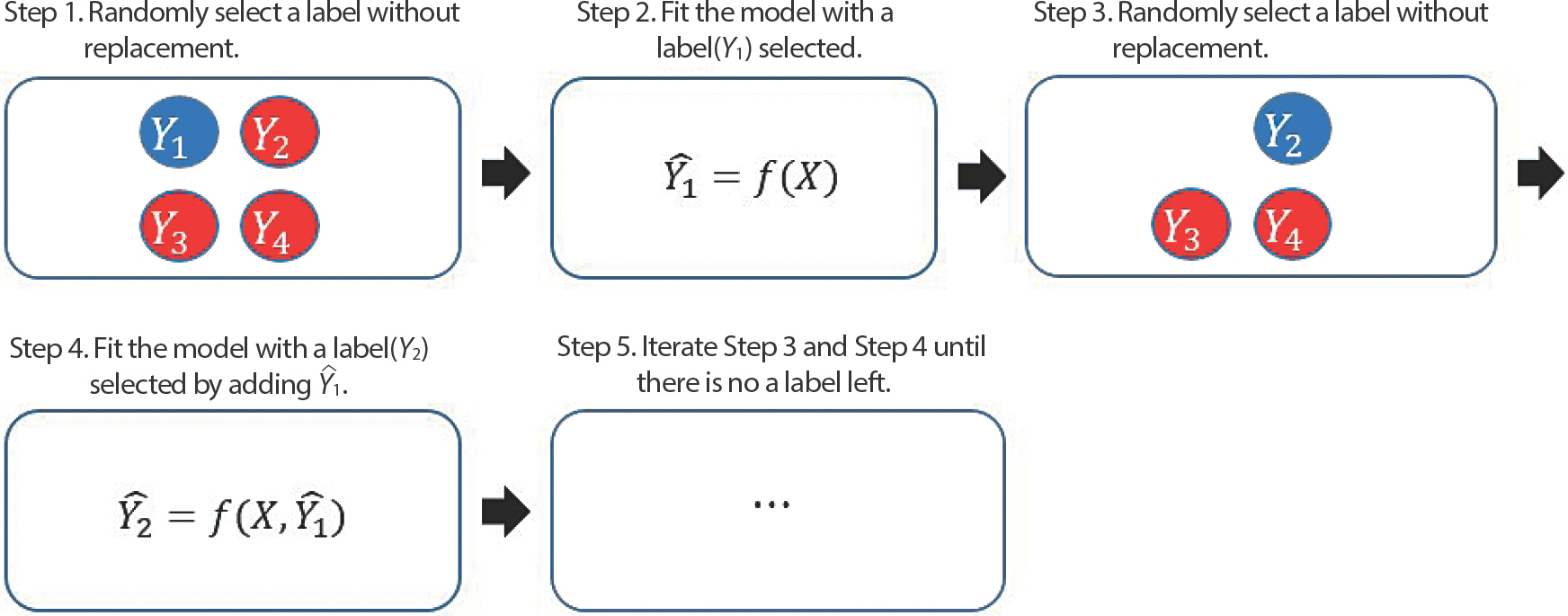
데이터 분석
예측 모형 적합에 앞서 각 통합데이터 – ‘데이터 (A)’, ‘데이터 (B)’, ‘데이터 (C)’ – 의 변수 중 지역사회통합돌봄 선별 평가 문항 일부 값을 제대로 입력하지 않은 특정 지역의 자료는 전처리 단계에서 제외하였다. 자료의 결측치들 중 원자료의 복원 가능한 경우 리코딩 하였으며, 이후 남은 결측치들은 결측치 대체 방법으로 잘 알려진 MissForest [16]를 통해 대체하였다. 또한, 모든 설명변수의 단위를 맞추기 위해 최소-최대 정규화를 통해 0과 1 사이로 변경하였다.
분석 모형은 이진형 분류에서는 로지스틱 회귀 모형, 라쏘, 랜덤포레스트, XG부스트, 서포트 벡터 머신(Support vector machine, SVM)을 활용하였고[17,18], 앙상블 체인 분류기에서는 성능이 우수한 것으로 알려진 랜덤포레스트를 기반으로 분석을 진행하였다[19,20]. 전체 데이터는 훈련 데이터와 시험 데이터를 3대 1로 나누어 모형 적합 및 예측 성능 평가를 진행하였는데, 훈련 데이터에서는 10-fold 교차검증 방법을 활용하여 각 기계학습 모형마다 최적의 초매개변수의 조합을 선택하였다(Table 1). 교차검증 과정 중 특정 레이블이 나타나지 않는 문제를 피하기 위해 학습 데이터와 검증 데이터의 레이블 발생 비율을 맞추어 데이터를 나누는 층화된 교차검증[21]을 고려하여 데이터를 분할하였다.
Table 1.
Hyperparameters considered for each algorithms
분류 모형의 평가를 위한 성능지표는 주로 이진 분류 문제를 대상으로 모형의 예측 결과와 실제 데이터의 값을 비교하여 보여주는 혼동 행렬에서 정밀도와 재현율의 조화평균으로 이뤄진 ‘ F1 점수(F1)’ [22]를 활용하였고, 개별 레이블 별로 가장 큰 F1을 갖는 알고리즘을 각 레이블의 예측 모형으로 선택하였다. 기계학습에서 가장 좋은 예측 성능 모형의 F1이 0.8 이상인 레이블에 대해 어떤 설명변수들이 모형의 예측 성능 향상에 기여하는지를 변수 중요도를 통해 확인하였다. 모든 분석은 통계 소프트웨어 R version 4.0.3을 통해 진행하였다.
연구 결과
욕구 예측을 위한 모형에서는 ‘경제’ 욕구 예측에 ‘데이터 (A)’를 활용한 SVM 모형이 가장 높은 예측성능(F1=0.72)을 가지는 것으로 나타났다. 이는 ‘데이터 (A)’와 달리 ‘데이터 (B)’와 ‘데이터 (C)’는 해당 목표변수의 클래스가 심각하게 불균형한 상태에 있어 예측 성능이 저하된 것으로 확인되었다. 이외에 ‘일상생활 유지’, ‘건강’, ‘생활환경’ 레이블들은 ‘데이터 (C)’에서 예측 성능이 가장 높은 것으로 나타났다. ‘일상생활 유지’ 레이블은 SVM 모형을 적합했을 때 예측 성능이 F1은 0.87로 가장 높게 나타났으며, ‘건강’ 레이블과 ‘생활환경’은 앙상블 체인 분류기를 적합하였을 때 예측 성능이 가장 높았는데, F1은 각각 0.87과 0.77로 나타났다(Table 2). 이 중 F1≥ 0.8인 ‘일상생활 유지’와 ‘건강’ 레이블의 예측 모형에 대한 설명변수별 변수 중요도를 살펴본 결과 ‘일상생활 유지’에서는 영양 관리와 거주지 유형이 예측에 도움을 주는 설명변수로 확인되었고, ‘건강’에서는 신체 활동 점수와 약 복용 여부가 예측에 도움을 주는 설명변수로 확인되었다(Figure 3A).
Figure 3.
Variable importance of the labels related to needs, problem domain and major and minor classification of resources. (A) The labels related to needs, (B) The labels related to problem domain, (C) The labels related to major classification of resources. (D) The labels related to minor classification of resources.
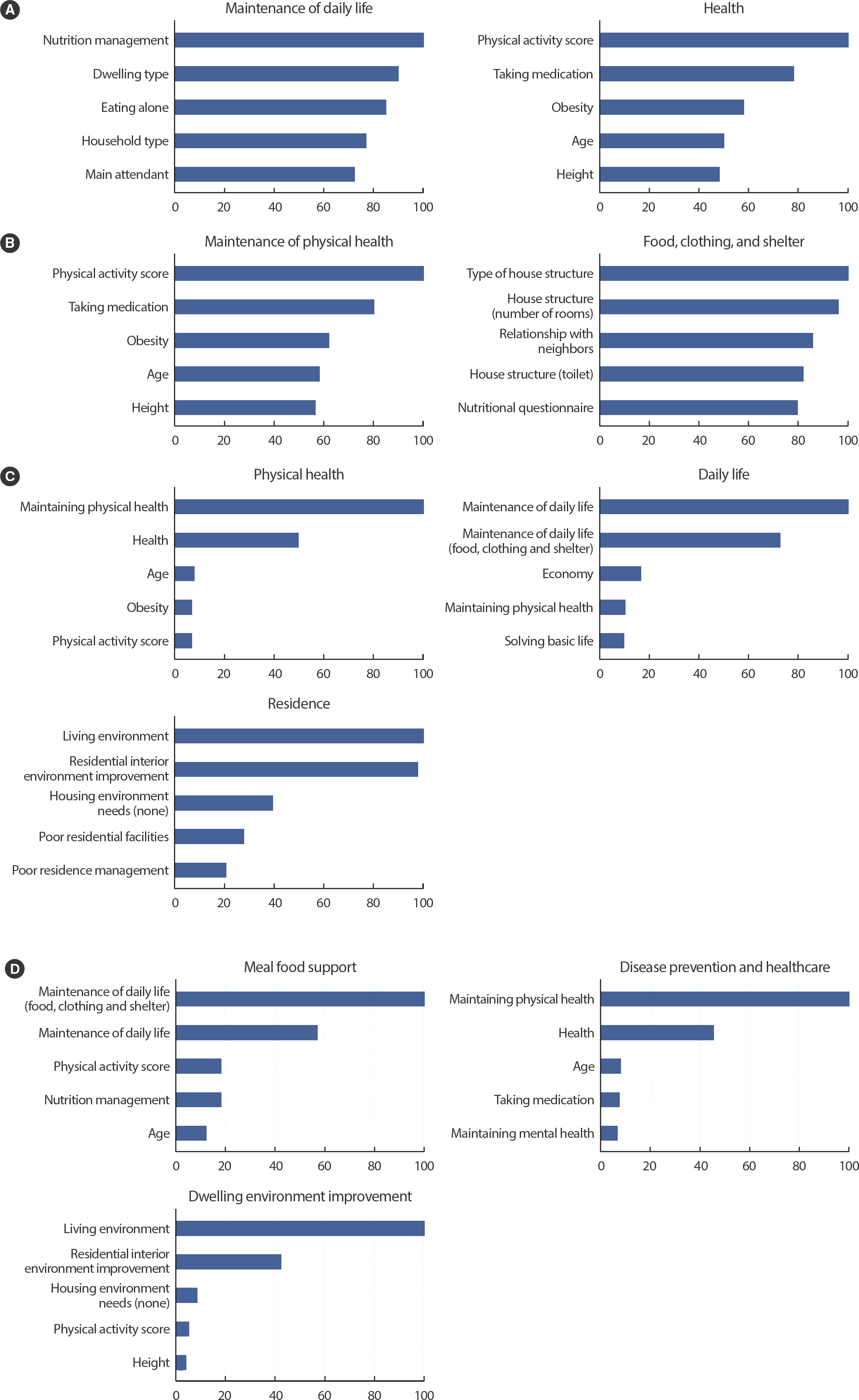
Table 2.
Prediction performance of the labels related to needs, problem domain and major and minor classification of resources
문제 예측을 위한 모형에서는 ‘일상생활 해결’ 예측에 ‘데이터 (A)’를 활용한 라쏘 모형이 가장 높은 예측성능(F1=0.73)을 가지는 것으로 나타났다. 마찬가지로 ‘데이터 (B)’와 ‘데이터 (C)’의 경우 해당 목표변수 클래스의 불균형 문제로 인한 예측 성능 저하가 확인되었다. ‘신체적 건강 유지’ 레이블의 경우 ‘데이터 (B)’를 랜덤포레스트로 적합하였을 때(F1=0.83), ‘주거 내부 환경 개선’ 레이블에서는 ‘데이터 (C)’를 앙상블 체인 분류기로 적합하였을 때(F1=0.76), 그리고 ‘기초 생활 해결’에서는 ‘데이터 (C)’를 SVM으로 적합하였을 때(F1=0.86) 예측성능이 가장 높았다(Table 2). 이 중 F1≥ 0.8를 만족하는 ‘신체 건강 유지’와 ‘의식주’ 레이블의 예측 모형의 설명변수별 변수 중요도를 살펴보았을 때, ‘신체 건강 유지’에서는 신체활동 점수와 약 복용 여부가 예측에 도움을 주었고, ‘의식주’에서는 가구 구조와 방의 개수가 예측에 도움을 주는 것으로 확인되었다(Figure 3B).
자원 대분류 예측을 위한 모형에서는 ‘데이터 (B)’에서 ‘신체 건강 및 보건의료’ 레이블에 대해 랜덤포레스트를 사용하였을 때(F1=0.89), ‘일상생활’ 레이블에 랜덤포레스트를 사용하였을 때(F1=0.95), ‘보호 및 돌봄 요양’ 레이블에 앙상블 체인 분류기 알고리즘을 사용하였을 때(F1=0.55) 예측성능이 가장 높았다. ‘보호 및 돌봄 요양’의 경우 다른 레이블에 비해 성능이 낮은데 이는 해당 목표변수에 대한 데이터의 불균형이 심각하기 때문으로 판단하였다. ‘데이터 (C)’의 경우 ‘정신 건강 및 심리 정서’ 레이블에 대해 랜덤포레스트를 사용하였을 때(F1=0.77), ‘주거’ 레이블에 XG부스트를 사용하였을 때(F1=0.92) 예측성능이 가장 높은 것을 확인하였다(Table 2). 이 중 F1≥ 0.8을 만족하는 ‘신체 건강’, ‘일상생활’, ‘주거’ 레이블의 예측 모형의 설명변수별 변수 중요도는 ‘신체 건강’에서는 문제 영역의 신체 건강 유지와 욕구 영역의 건강 순으로, ‘일상생활’에서는 욕구 영역의 일상생활 유지와 문제 영역의 일상생활 유지(의식주) 순으로, ‘주거’에서는 욕구 영역의 생활환경과 문제 영역의 거주지 내부 환경 개선 순으로 예측에 도움을 주는 것으로 나타났다(Figure 3C).
자원 중분류 예측을 위한 모형은 ‘데이터 (A)’에서 ‘생활용품 지원’(F1=0.70)과 ‘정서발달 및 치유 지원’(F1=0.71) 레이블에 랜덤포레스트를 사용한 경우, ‘데이터 (B)’에서 ‘질병 예방 및 건강 관리’ 레이블에 랜덤포레스트를 사용한 경우(F1=0.83), ‘데이터 (C)’에서 ‘식사 식품 지원’ 레이블에 랜덤포레스트를 사용한 경우(F1=0.90), ‘주거환경 개선’ 레이블에 XG부스트 알고리즘을 사용한 경우(F1=0.91) 모형의 예측성능이 가장 높은 것으로 확인되었다(Table 2). 이 중 F1≥ 0.8을 만족하는 ‘식사 식품 지원’, ‘질병 예방 및 건강 관리’, ‘주거환경 개선’ 레이블의 예측 모형의 설명변수별 변수 중요도를 살펴보았을 때, ‘식사 식품 지원’에서는 문제 영역의 일상생활 유지(의식주)와 욕구 영역의 일상생활 유지 순으로 예측에 도움을 주었고, ‘질병 예방 및 건강 관리’에서는 욕구 영역에서 일상생활 유지 및 문제 영역에서 건강 순으로 예측에 도움을 주었으며, ‘주거환경 개선’에서는 욕구 영역의 생활환경과 문제 영역의 거주지 내부 환경 개선 순으로 예측에 도움을 주었다(Figure 3D).
이진형 분류에서 F1은 관심 있는 사건의 발생률이 높을수록 더 높은 예측 성능을 제공하는 지표로 알려져 있다[22]. 본 연구 결과에서도, 욕구 영역의 ‘건강’ 레이블과 자원 영역의 ‘신체건강 및 보건의료’, ‘보호 및 돌봄 요양’, ‘정신 건강 및 심리 정서’ 레이블들을 제외한 나머지 분석결과에서 발생률이 높은 데이터셋을 통해 분석을 하였을 때, F1 기준 예측 성능이 가장 높은 것으로 나타났다.
고찰 및 결론
본 연구에서는 우리나라 사회복지통합관리망 체계에서 축적된 자료들(통합사례관리 자료, 노인돌봄서비스 자료, 지역사회통합돌봄 자료)을 연결한 통합데이터에 기계학습 모형을 적용하여 지역사회 노인의 돌봄 욕구 및 지역사회 자원 연계를 예측함으로써 빅데이터 기반의 욕구-자원 연계 가능성과 적정성을 검토하고자 하였다. 각 자료를 서로 다르게 조합하여 결합한 세 개의 통합데이터를 구축하여 기계학습 모형을 적용한 결과 욕구 및 문제 영역(세부 욕구)과 자원의 대분류 및 중분류 레이블들에 대한 예측 성능을 확인하였고, 그중 ‘데이터 (C)’에서 다수의 레이블에 대한 예측 성능 향상이 있었다. 먼저, ‘데이터 (A)’에 비해 ‘데이터 (C)’에서 F1이 0.1 이상 향상된 레이블은 욕구에서 ‘일상생활 유지’, ‘건강’, ‘생활환경’, 문제영역에서 ‘주거 내부 환경 개선’, ‘신체 건강유지’, ‘의식주 관련 일상생활 유지’, 자원 대분류에서 ‘신체 건강 및 보건의료’, ‘보호 및 돌봄 요양’, ‘주거’, 그리고 자원 중분류에서 ‘식사 식품 지원’, ‘질병예방 및 건강관리’, ‘주거환경 개선’이었다. 또한 ‘데이터 (B)’에 비해 ‘데이터 (C)’에서 F1이 0.1 이상 향상된 레이블은 욕구에서 ‘생활환경’, 문제영역에서 ‘주거 내부 환경 개선’으로 관찰되었다. 이를 통해, 예측 성능이 향상된 자원 대분류 및 중분류에 해당하는 레이블들은 지역사회통합돌봄 자료의 설명변수들이 예측 성능 향상에 도움을 주고 있을 가능성을 확인하였다.
본 연구에서 최종적으로 도출한 기계학습 기반 예측 모형을 통합사례관리 자료에 적용하여 욕구-자원 예측의 가능성을 검토하기 위한 분석 결과, 욕구에서 ‘일상생활 유지’와 ‘건강’, 문제 영역에서 ‘신체 건강 유지’와 ‘의식주’ 레이블이, 자원 예측을 위한 모형 분석에서는 자원 대분류에서 ‘신체건강’, ‘일상생활’, ‘주거’ 레이블이, 자원 중분류에서는 ‘식사 식품 지원’, ‘질병 예방 및 건강관리’, ‘주거환경 개선’ 레이블이 F1≥ 0.8을 만족하여 우수한 성능으로 예측이 가능함을 확인하였다. 이 결과는 통합사례관리 자료의 광범위한 정보를 활용한 예측 모형 개발의 가능성을 시사한다. 빅데이터 기반의 접근은 기존 장시간에 걸친 일대일 방문상담을 통한 욕구 조사와 개별 사례관리자의 판단에 따른 자원 연계 방식에서 발생하는 현장 사례관리자들의 업무 부담과 제한된 정보 접근 하의 사람에 따른 욕구 조사 및 자원 연계 결정의 불일치를 줄이며 지역사회 노인들의 욕구 파악과 자원 연계 과정을 효과적으로 지원할 수 있는 가능성을 실증 자료를 통해 확인했다는 의의를 가진다. 또한, 본 노인 돌봄 빅데이터를 활용한 욕구-자원 서비스 예측 모델은 고도화를 통해 각 욕구 및 자원을 예측하는 데에 주요한 도움을 줄 수 있는 설명변수들을 파악하여 통합사례관리 절차에서 실무자의 의사결정에 참고할 수 있는 실질적이고 구체적인 정보를 제공할 수 있다는 점에서 강점을 가진다.
본 연구의 한계점은 각 자료를 결합한 방식에 따라 통합데이터의 레이블 발생 비율이 다르게 나타난다는 것이다. 이는 통합데이터 구축을 위한 자료 간 결합 시 공통 ID를 갖는 분석 대상자 수가 상당히 달라지기 때문이다. 또한, 본 연구에서 활용한 세 개의 한국의 현재 가용한 노인 돌봄 빅데이터를 모두 정제·통합한 ‘데이터 (C)’의 경우 가용한 정보가 가장 많아 이 통합 데이터셋에서 다수의 레이블에 대한 예측 성능 향상이 있었으나, 공통된 분석 대상자 수가 상당히 줄어들어 해당 결과를 일반화하는 데 어려움이 있을 수 있다. 이는 향후 의미 있는 노인 돌봄 빅데이터 모델 개발과 활용은 해당 데이터셋 구축과 관리 과정의 개선과 고도화가 전제되어야 함을 시시한다. 마지막으로, 본 연구는 자료의 한계로 통합사례관리를 통해 노인에게 제공된 자원 및 지원서비스에 대한 결과로 노인의 욕구가 얼마나 충족되었는지에 대해서는 파악할 수가 없다는 한계를 가진다.


