서 론
체계적 문헌고찰(systematic review)과 메타분석(meta-analysis)은 대상문헌의 선택에 있어서 투명성을 지니며 통합된 효과크기(effect size)를 제시하여 근거기반의료(evidence based medicine, EBM)를 위한 올바른 의사결정을 할 수 있게 한다[1].
메드라인(MEDLINE) 통계에 따르면 메타분석의 태동기인 1990년도 272편의 연구가 검색되는데 이 수는 2000년 849편, 2010년 4,691편, 그리고 2014년에는 10,427편에 이를 만큼 급증하는 추세를 나타내며 의학에 있어서 중요한 연구방법론으로 자리잡고 있음을 알 수 있다[2]. 이러한 메타분석의 연구방법론에 대해 국내에서는 다수의 논문들과 저서가 소개하고 있다[3-6]. 그러나 이들 대부분이 개념적이거나 또는 이론적인 접근에만 치중하고 있어 실제 이를 적용하여 논문을 작성하기에는 구체적인 적용 방법상의 문제점을 해결하지 못하는 한계가 있었다.
Wallace et al. [7]은 메타분석 소프트웨어 STATA, R, MIX, CMA, RevMan, Meta-Analyst 등에 대한 특성들을 보고하였다. RevMan은 무료이며 기본적인 메타분석은 가능하지만 조절변수의 이질성 파악 등 대부분의 기능이 제한적이다. CMA는 상용프로그램이며 그래픽 사용자 입력방식(graphical user interface)으로 초보자가 이용하기에 적합하여 RevMan보다는 더 많은 기능을 실행하나 여전히 확장성은 제한적이다. R과 STATA는 확장성이 좋아 현재까지 개발된 중재 메타분석에서부터 진단검사 메타분석에 이르기까지 다양한 분석기능이 가능하다. R은 무료 프로그램으로 다양한 분야에서 분석방법이 개발되어 있으나 기본적으로 통계 전공자를 위한 프로그래밍(programming) 언어로서 이를 구현하기에는 상당한 학습이 필요하다. 다만 최근에는 R을 이용한 메타분석방법이 체계적으로 개발되어 있어 향후 그 쓰임새가 증가할 것으로 예상한다. STATA는 상용프로그램이며 모듈(module)별로 통계방법이 개발되는데 특히 메타분석 통계방법들은 모두 STATA 저널에서 검증을 거치기에 표준적이고 신뢰할 수 있다.
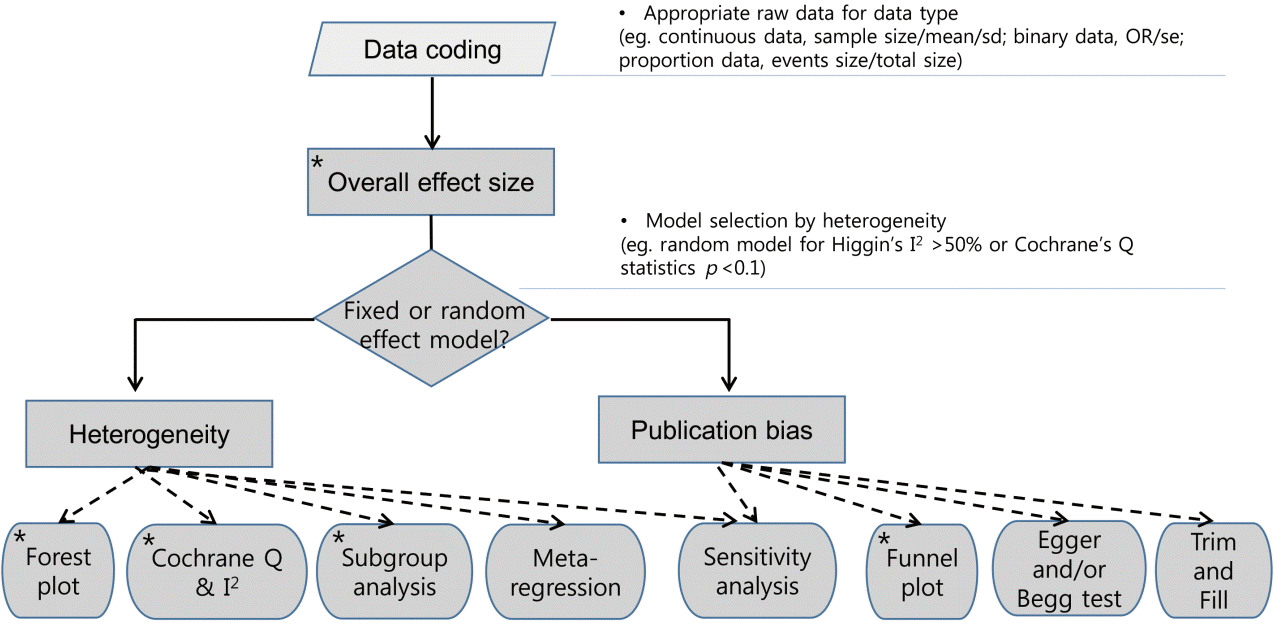
따라서 본 연구는 통계학이 전공분야가 아닌 대다수의 국내 연구자들이 보다 쉽게 이해하고 실행할 수 있도록 메타분석에 특화된 STATA 프로그램을 이용하여 메타분석을 실행하는 데 있어 연구자가 범하기 쉬운 오류 및 실수를 최소화하고 효과적인 연구수행을 위한 방법 및 가이드라인(guideline)을 제시하고자 한다(Figure 1).
연구 방법
문헌 검색 및 개별 문헌들의 질 평가(quality assessment)는 개념적인 이해와 연구자 상호 간의 협업으로써 수행되는 것으로 Cochrane handbook [8]을 참고하기 바란다. 대상 문헌들을 선택하였다면 개별 연구들에서 효과크기를 추출하여 이를 STATA에 맞게 코딩(coding)한다(Table 1).
예제자료
본 연구에서는 효과크기가 평균의 차이(difference in means)로 나타내어지는 연속형 자료(continuous data), 위험도비(odds ratio, risk ratio, 또는 hazard ratio)로 나타내어지는 생존형 자료(time to event data), 그리고 백분율로 나타내어지는 유병률 자료(proportion or rate data)를 가지고 통합효과크기(overall effect size) 산출, 이질성(heterogeneity) 확인 및 원인파악, 그리고 출판편향(publication bias) 검토를 설명토록 한다(Table 1). 그렇지만 일반적으로 의학에서는 상관계수(correlation coefficient, r)로 나타내어지는 효과크기의 활용도는 떨어짐으로 이에 대한 설명은 제외하였다.
연속형 자료
척수손상 동물모델에서 줄기세포치료에 따른 방광기능 효과를 메타분석한 연구에서 결과지표 배뇨 시 압력(voiding pressure)을 예제로 사용하였다[9]. 전체 연구 수는 11개였고 실험군 94개와 대조군 93개로 이루어졌다. 부집단(subgroup) 1은 contusion model 그리고 0은 transection and hemisection model로 구분하였다. 연구결과에 따르면 WMD(weighted mean difference)는 -6.35 (95% CI: -8.22, -4.48)였고 Higgins’ I2는 77.2% 그리고 Cochrane’s Q statistics p-value는 0.001이었다.
생존형 자료
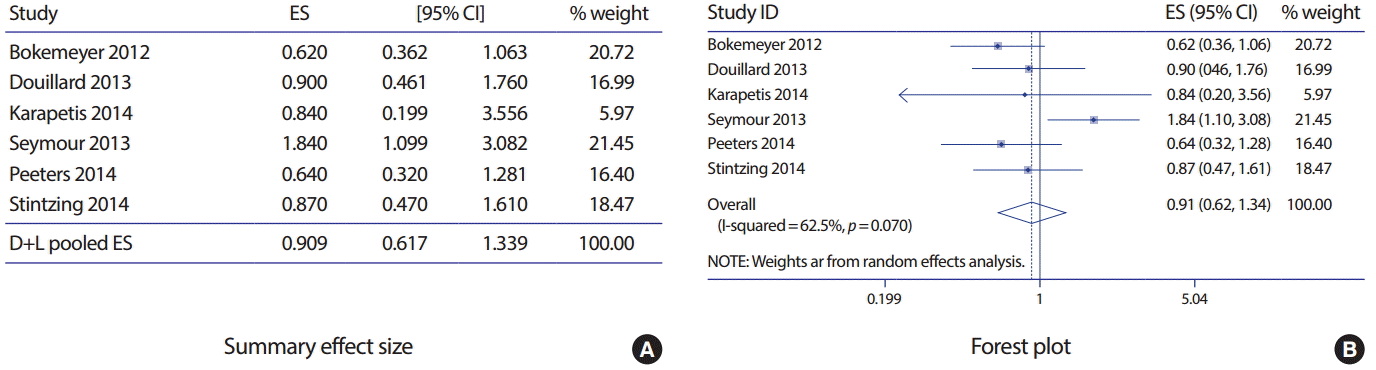
Cetuximab and panitumumab의 대장암 치료 시 B-Raf proto-oncogene (BRAF) 변이에 따른 위험도(Hazard Ratio, HR)를 메타분석한 연구에서 결과지표 전체생존율(overall survival, OS)을 예제로 사용하였다[10]. 전체 연구 수는 6개였고 부집단 1은 fluorouracil을 사용한 군 그리고 0은 fluorouracil을 사용하지 않은 군으로 구분하였다. 연구결과에 따르면 HR은 0.91 (95% CI: 0.62, 1.34)였고 Higgins’ I2는 50% 그리고 Cochrane’s Q statistics p-value는 0.007이었다.
메타분석모형선택
중재법 메타분석(intervention meta-analysis)의 통합효과크기를 산출하기 위해 일반적으로 고정효과모형(fixed effects model)과 변량효과모형(random effects model)이 사용된다.
고정효과모형
고정효과모형은 개별 연구들의 중재(intervention)에 따른 공통효과크기(common effect size)가 존재하며 연구들 간의 효과 차이는 표본추출오차(sampling error) 때문이라 가정한다. 따라서 고정효과모형은 대상집단과 중재방법이 동질하다고 판단될 경우 고려할 수 있으며 일반적으로 이질성을 나타내는 지표인 Higgins’ I2 가 50% 이하인 경우 또는 Cochrane Q statisticsp-value가 유의하지 않은 경우(p≥ 0.1) 고려될 수 있다(Cochrane handbook; 9.5.2. Identifying and measuring heterogeneity) [8]. 고정효과모형은 inverse variance method, mantel-haenzel method, 그리고 peto method가 있으며 일반적으로 inverse variance method가 사용된다. 개별 모형에 대한 상세한 내용은 Cochrane handbook [8] 9장을 참고하기 바란다.
STATA에서는 고정효과모형(mantel-haenzel method)이 default로 설정되어 있으며 옵션에 ‘fixed’를 넣어도 동일한 결과를 나타낸다.
변량효과모형
변량효과모형은 개별연구들의 중재효과에 대해 공통의 효과크기를 추정하기보다는 효과크기의 분포(distribution)를 추정하며 정규분포를 따른다고 가정한다. 따라서 연구들 간의 효과 차이는 표본추출오차와 연구들 간의 실체적 차이(true difference)를 동시에 고려한다[11]. 일반적으로 연구들 간의 이질성이 높을 때(Higgins’ I2 >50% or Cochrane’s Q statistics p < 0.1) 변량효과모형이 고정효과모형보다 보수적인 추정치를 제공하여 권고된다(Cochrane handbook; 9.5.4. Incorporation heterogeneity into random-effects models) [8]. 연구들 간의 실체적 차이(tau)가 적거나 0인 경우 두 모형은 동일한 값을 나타낸다.
STATA 명령어
개별 연구들이 여러 통계 값들[eg. d(mean difference), OR/RR/HR, r(correlation)]로 나타내어져 있다면 이들을 표준화된 하나의 효과크기로 상호 변환할 수 있다(Chapter 7. Converting among effect sizes. 45-49) [1]. 이렇게 직접 개별 연구들의 효과크기를 계산하였다면 자료의 유형에 상관없이 STATA 명령어 metan에 효과크기와 표준오차(standard error)를 순서대로 넣어주면 통합된 효과크기 계산이 가능하다.
Table 2는 메타분석을 위한 STATA 명령어를 정리한 것이다. 통합효과크기 계산과 숲그림(forest plot)을 작성을 위한 metan과 metaprop, 이질성의 원인을 파악하기 위한 메타회귀분석(meta-regression)은 metareg, 그리고 출판편향(publication bias)을 확인하기 위해서는 metafunnel, metabias, 그리고 metatrim의 명령어를 사용한다(Table 2). 상기 옵션들은 기본적으로 효과크기와 표준오차의 변수를 순서대로 입력하며 각 자료의 유형과 옵션은 아래에서 상세히 설명토록 한다.
생존형 자료와 이분형 자료(dichotomous data)의 경우 효과크기가 비(ratio) 형태인 HR 또는 OR로 나타내어지기에 메타분석 과정이 동일하다. 물론 이분형 자료의 경우 개별연구의 treatment 그룹과 control 그룹의 전체표본 수와 사건발생 수를 모두 추출할 경우 STATA에서 보다 간단히 처리할 수 있으며 이에 대한 설명은 참고문헌으로 대신한다[12].
결 과
통합효과크기 산출
연속형자료
연속형 자료일 경우 기본적으로 treatment 그룹과 control 그룹의 표본 수, 평균, 그리고 표준편차(standard deviation)를 순서대로 넣어야한다. Treatment 그룹과 control 그룹의 순서는 효과크기를 해석하기 쉬운 방향으로 임의로 넣어도 무관하다.
metan t_n t_m t_sd c_n c_m c_sd, label(namevar = study) nostandard random by(g) textsize(130)
쉼표 뒤로는 옵션들이 위치하는데 옵션의 순서는 상관이 없으며 label(name = study)는 study라는 변수를 개별 연구들의 이름으로 설정하는 것이고 nostandard는 standardized mean difference (SMD)를 사용하지 말고 weighted mean difference (WMD)를 사용하라는 것이고, random은 이질성 추정을 Mantel-Haenszel 모형에 근거한 변량효과모형을 사용하며, by(g)은 부집단별로 결과를 제시하며 마지막으로 text-size(130)은 forest plot 내의 글자크기를 나타내는 것이다. 또한 metan 명령어는 forest plot을 자동으로 제시한다. 이 외 출력된 내용에 대한 설명은 참고문헌으로 대신한다[12].
Figure 2에서 전체 효과크기는 -6.346 (95% CI: -8.215, -4.477)로서 통계적으로 유의한 값을 나타낸다. Higgins’ I2 는 77.2% 그리고 Cochrane’s Q statistics p-value는 0.001 미만으로서 이질성이 존재한다는 것을 알 수 있다. 부집단 분석결과 contusion model과 transection and hemisection model에 따라 차이를 보이고 있으며 transection and hemisection model이 더 낮은 값을 나타낸다.
Table 1의 연속형 자료인 Kim et al. [9] 원저는 줄기세포 실험데이터로서 실험실적 환경을 제외하고는 다른 변수들이 동일하다고 가정하였으며 동일한 결과지표를 사용하였기에 WMD를 사용하였다. WMD는 Cochrane에서는 mean difference 또는 difference in means으로 지칭하며 개별 연구들에서 동일한 단위(scale)로 얻어낸 결괏값일 경우 사용이 가능하며 해석이 용이하다는 장점이 있다[Cochrane handbook; 9.2.3.1. 9 The mean difference (or difference in means)] [8]. 그렇지만 Mean difference는 비교 그룹 간 절댓값의 차이를 표본 수와 표준오차의 가중치로 추정한 것으로 여기에 개별 연구들을 각각의 공통표준편차(pooled standard deviation)로 나누어준 SMD와의 용어 혼동 가능성이 있으므로 사용을 권고하지 않는다. 따라서 개별 연구들의 효과크기를 종합하는 메타분석 방법론에 충실하고 연구들 간의 표준화된 지수로서 비교하기 위해서는 SMD를 사용하는 것이 바람직하다[13]. 또한 표본이 작을 경우 이를 SMD를 교정해주는 Hedges’ g를 사용하여야 한다[14]. 따라서 상기 자료를 일반적인 SMD (hedges’ g)와 변량효과모형을 설정하는 명령어는 다음과 같다.
metan t_n t_m t_sd c_n c_m c_sd, label(namevar = study) hedges random by(g)
생존형 자료
명령어는 동일하게 metan을 사용하며 HR과 표준오차를 순서대로 넣는다. 일반적으로 개별 연구들이 HR과 95% CI를 제시하는데 metan 명령어 사용을 위해서는 HR과 95% CI에 자연로그를 취하여 로그변환된 HR과 표준오차를 계산하여야 한다. 로그변환을 시키는 이유는 HR의 경우 지수변환된 상태로서 ‘0’이 하한설정으로 되어 있어 이를 풀어주기 위한 것이다(Chapter 5. Effect sizes based on binary data.33-39) [1]. 표준오차는 HR의 95% CI 상·하한에 자연로그를 취한 후 상한에서 하한을 뺀 값을 3.92로 나누어주면 쉽게 얻을 수 있다[(ln(95CIhigh) - ln(95CIlow))/3.92].
metan lnhr selnhr, label(namevar = study) eform random text-size(150)
lnhr은 로그변환된 HR이며 selnhr은 표준오차이다. 쉼표 뒤로는 옵션들이 위치하는데 나머지는 연속형 자료의 설명과 동일하며 eform은 로그변환된 수치로써 계산을 하기 때문에 HR로의 해석을 위해서는 다시 이를 지수변환 시키라는 명령어이다. 만약 생존분석 연구에서 HR과 관련 통계 값을 충분히 제시하지 않고 Kaplan-Meier 생존곡선만 있는 경우 생존곡선에서 HR을 계산할 수 있는 방법도 있으니 참고하기 바란다[15].
Figure 3에서 전체 효과크기 HR이 0.909 (95% CI: 0.617, 1.339)로서 통계적으로 유의하지 않은 값을 나타낸다. Pietrantonio, et al. [10] 원저에서는 부집단 분석결과를 따로 제시하지 않고 있으나 본 연구에서는 fluorouracil의 사용 여부에 따른 부집단 분석을 옵션 by를 이용하여 아래와 같이 실시하였다.
metan lnhr selnhr, label(namevar = study) eform random by(g)
fluorouracil을 사용한 그룹의 HR은 0.737 (95% CI: 0.540, 1.005)로 위험도가 약 26% 감소하였고 통계적으로 경계선 값을(p = 0.054) 나타내었다. 반면 fluorouracil을 사용하지 않은 그룹의 HR은 1.681 (95% CI: 1.028, 2.748)을 나타내어 위험도가 통계적으로 유의하게 약 68% 증가하였다(p = 0.038). 따라서 fluorouracil의 치료 여부에 따른 HR의 차이가 있음을 확인할 수 있다.
유병률 자료
유병률 자료는 통상 비율(proportion or rate)로 표시되며 질병의 이환율, 사망률, 항생제 내성률 등을 나타내는 지표로 자주 활용되고 있다. 메타분석을 위해서 개별 연구들의 효과크기가 다른 통계량이 제시되지 않고 비율로만 나타내어져 있거나 비율 자체가 연구의 주요 관심사일 때는 이에 대한 통합효과크기를 계산하여야 한다.
명령어는 metaprop를 사용하며 사건발생 빈도(event size) 와 전체 표본 수(sample size)를 순서대로 넣는다.
metaprop f n, random by(g) label(namevar = study)
쉼표 뒤로는 옵션들이 위치하는데 random은 inverse variance 모형에 근거한 변량효과 모형을 사용한다는 뜻이다.
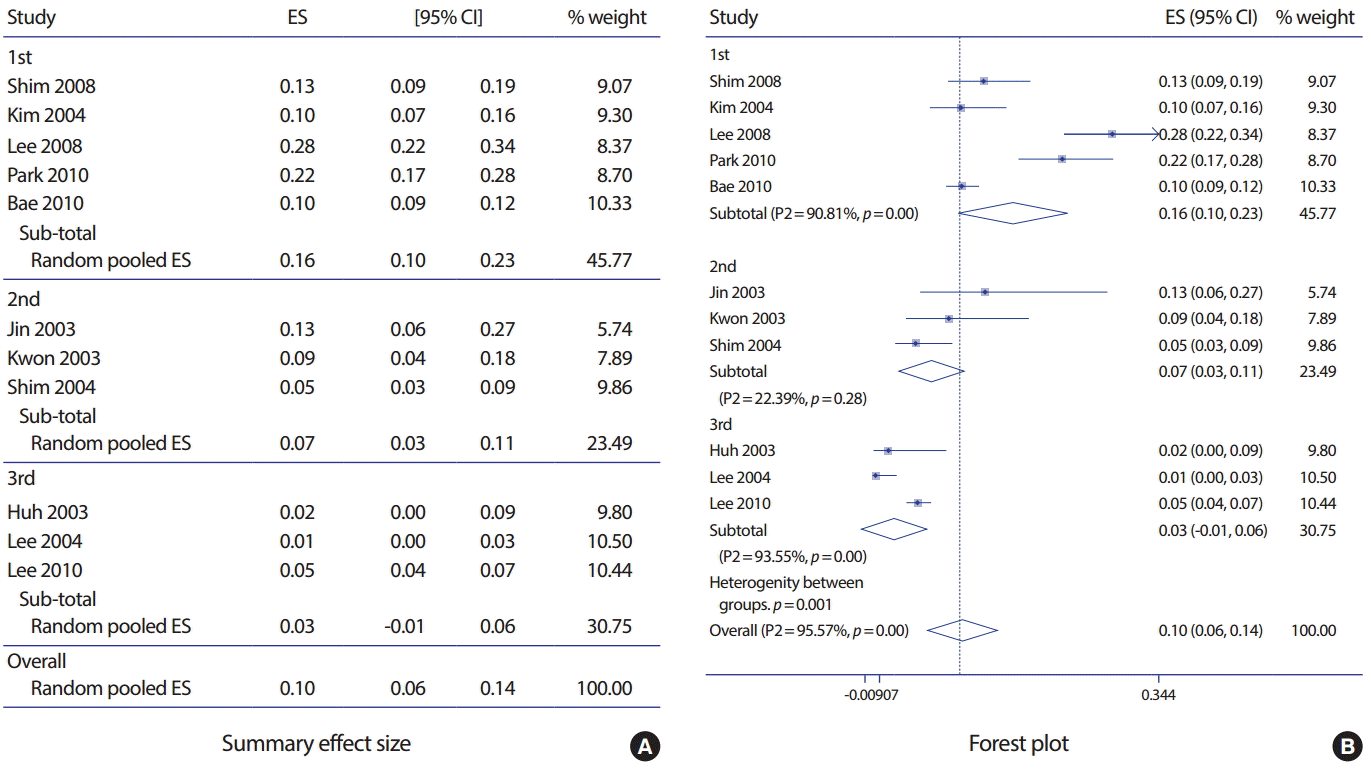
Figure 4에서 전체 효과크기 항생제 내성률은 0.10 (95% CI: 0.06, 0.14)이다. Higgins’ I2 는 95.57% 그리고 Cochrane’s Q statistics p-value는 0.01 미만으로서 이질성이 존재한다는 것을 알 수 있다. 항생제 세대별 부집단 분석결과를 살펴보면 1세대는 0.16 (95% CI: 0.10, 0.23), 2세대는 0.07 (95% CI: 0.03, 0.11), 그리고 3세대는 0.03 (95% CI: -0.01, 0.06)으로서 세대가 높아질수록 항생제 내성률이 감소하는 경향을 나타낸다.
이질성 확인
메타분석에서 얻어낸 통합효과크기를 제대로 해석하려면 연구들 간의 이질성 유무를 확인하고 만약 유의한 조절변수(moderator)가 있다면 이를 검정하고 보고하여야 한다. 이러한 이질성의 원인은 우연(chance), 연구설계(study design)의 차이, 연구환경, 그리고 표본집단의 인구사회학적 요인에 이르기까지 매우 다양하다.
시각적 확인: 숲그림(forest plot)
개별 연구들의 통합효과크기와 95% CI를 제시하여 연구 내 변동과 연구 간 변동을 쉽게 파악할 수 있도록 하는 것이 숲그림이다[16]. STATA에서는 metan 명령어의 기본 변수만 넣어주면 숲그림은 자동으로 생성된다(Figures 2-4).
연속형 자료의 숲그림에서 연구 내 변량이 큰 것은 Mitsui 2003, WBPark 2010_2, Telmeltas 2009_1, 그리고 Telmeltas 2009_2인 것을 알 수 있고 연구 간 변량이 큰 것은 Mitsui 2003, WBPark 2010_2, 그리고 Telmeltas 2009_1인 것을 알 수 있다(Figure 2). 생존형 자료의 숲그림에서 연구 내 변량이 큰 것은 Karapetis 2014이며 연구 간 변량이 큰 것은 Seymour 2013인 것을 알 수 있다(Figure 3). 유병률 자료의 숲그림에서 연구 내 변량이 큰 것은 Jin 2003이며 연구 간 변량이 큰 것은 Huh 2003, Lee 2004, 그리고 Lee 2008인 것을 알 수 있다(Figure 4). 이처럼 숲그림을 통해 통합효과크기 각각에 대해 개별 연구들의 점추정과 구간추정 값을 전체적으로 볼 수 있다.
통계적 검정
개별 연구들의 이질성을 통계적으로 검정하는 방법으로는 Higgins’ I2 와 Cochrane Q statistics가 있다. Cochrane Q statistics은 개별 연구들의 중재효과가 통합효과 값으로부터 얼마나 멀리 떨어져 있는지를 χ2 검정을 통해 실시하는 것이다. 귀무가설은 이질성이 있다는 근거가 없다는 것이며 p-value 0.1을 통계적 유의수준으로 사용한다(Cochrane handbook; 9.5.2. Identifying and measuring heterogeneity) [8]. Higgins’ I2는 Cochrane Q statistics에서 자유도(degree of freedom)를 뺀 것을 다시 Cochrane Q statistics으로 나누어 준 값으로 이질성을 일관성 있게 정량화시킨다. 0%에서 40%는 이질성이 중요하지 않을 수 있으며(might not be important), 30%에서 60%는 중간 이질성(moderate heterogeneity), 50%에서 90%는 중대한 이질성(substantial heterogeneity), 그리고 75%에서 100%는 심각한 이질성(considerable heterogeneity)을 나타낸다(Cochrane handbook; 9.5.2. Identifying and measuring heterogeneity) [8].
연속형 자료의 숲그림(Figure 2)에서 Cochrane Q statistics p < 0.001로 귀무가설을 기각하고, Higgins’ I2는 77.2%로서 중대한 이질성이 존재한다고 판단할 수 있다. 생존형 자료의 숲그림(Figure 3)에서 Cochrane Q statistics p = 0.073로 귀무가설을 기각하고, Higgins’ I2는 50.5%로서 중간 이질성이 존재한다고 판단할 수 있다. 유병률 자료의 숲그림(Figure 4)에서 Cochrane Q statistics p < 0.01로 귀무가설을 기각하고, Higgins’ I2는 95.57%로서 심각한 이질성이 존재한다고 판단할 수 있다.
이질성 원인파악(subgroup analysis and meta-regression)
숲그림을 이용한 시각적 확인과 Cochrane Q statistics와 Higgins’ I2 이용한 통계적 검정으로부터 이질성이 의심된다면 이질성의 원인을 파악하기 위하여 부집단 분석과 메타회귀분석을 실시한다. 부집단 분석은 앞선 생존형 자료에서 fluorouracil을 사용한 그룹의 HR 0.737(95% CI: 0.540, 1.005)과 사용하지 않은 그룹의 HR 1.681 (95% CI: 1.028, 2.748)이 통계적으로 유의한 차이가 있음을 이미 나타내었고 연속형 자료(Figure 2)와 유병률 자료(Figure 4)에서도 각각의 부집단에 따른 효과크기 차이가 있음을 알 수 있었다. 따라서 부집단에 해당하는 변수들이 실제 조절변수(moderator)로 작용하는지를 알아보기 위하여 메타회귀분석을 실시한다. 메타회귀분석은 일반적으로 개별 연구들이 10개 이상일 때 추천된다(Cochrane handbook; 9.6.4. Meta-regression) [8].
예제로 사용된 두 연구의 원저[9,10]는 메타회귀분석까지는 실시되지 않았었다. 따라서 본 연구에서는 중대한 이질성 요인이라고 판단되는 변수를(1: contusion model, 0: transection and hemisection model [9]; 1: used fluorouracil, 0: no used fluorouracil [10]) 임의로 설정하여 메타회귀분석을 실시하였다. 유병률 자료는 항생제 세대를(0: 1st, 1: 2nd, 2: 3rd generation) 부집단 변수로 설정하였다.
STATA에서는 metareg이라는 명령어를 제공하는데 앞에서 살펴본대로 metan을 사용하여 통합효과크기를 먼저 산출한 후 이어서 분석하여야 한다. 메타회귀분석 방법에는 residual maximum likelihood (REML), method of moments (MM), 그리고 empirical bayes (EB) 등이 있으며 STATA에서는 REML이 default로 설정되어 있다.
metan t_n t_m t_sd c_n c_m c_sd, label(namevar = study) hedges random by(g)
metareg _ES g, wsse( _seES)
Metareg 명령어는 효과크기(_ES: metan에서 자동으로 생성됨)와 이질성의 원인으로 의심되는 변수(subgroup; 1: contusion model, 0: transection and hemisection model)를 순서대로 넣는다. 쉼표 뒤 옵션 wsse(within study standard error)는 연구 내 표준오차 변수(_seES: metan에서 자동으로 생성됨)를 지정한 것이다. Table 3의 연속형 자료에서 p값(p = 0.727)이 통계적으로 유의하지 않아 contusion model과 transection and hemisection model변수는 이질성 요인이 아닌 것으로 나타났다.
metan lnhr selnhr, label(namevar = study) eform random by(g)
metareg lnhr g, wsse(selnhr) eform
Metareg 명령어에 효과크기(lnhr; 로그변환된 HR)와 이질성의 원인으로 의심되는 변수(subgroup; 1: used fluorouracil, 0: no used fluorouracil)를 순서대로 넣는다. 쉼표 뒤 옵션 wsse에는 표준오차 변수(selnhr)를 넣는다. Table 3의 생존형 자료에서 p값(p = 0.048)이 통계적으로 유의하여 fluorouracil의 사용 여부가 이질성의 요인임을 알 수 있다. 따라서 부집단 분석(fluorouracil 사용한 그룹, HR 0.74; 미사용한 그룹, HR 1.68)에서도 알 수 있었듯이 fluorouracil의 치료는 HR을 낮추는 요인으로 해석할 수 있다.
metaprop f n, random by(g) label(namevar = study)
metareg _ES g, wsse( _seES)
Metareg 명령어에 효과크기(_ES: metaprop에서 자동으로 생성됨)와 이질성의 원인으로 의심되는 변수(subgroup; 0: 1st, 1: 2nd, 2: 3rd generation)를 순서대로 넣는다. 쉼표 뒤 옵션 wsse에 표준오차 변수(_seES)를 넣는다. Table 3의 유병률 자료에서 p값(p = 0.006)이 통계적으로 유의하여 항생제 세대가 이질성의 요인임을 알 수 있다. 따라서 부집단 분석(항생제 내성률 1세대 0.16, 2세대 0.07, 그리고 3세대 0.03)에서도 알 수 있었듯이 항생제 세대가 항생제 내성률 조절 변수임을 알 수 있다. 이 외 출력된 내용에 대한 설명은 참고문헌으로 대신한다[17].
출판편향(publication bias) 검토
출판편향은 개별 연구들의 특성과 결과에 따라 연구가 출판되거나 출판되지 않을 오류이다[18]. 일반적으로 통계적 유의한 연구결과일 경우 더욱 출판될 가능성이 높기 때문에 발생하는데, 이러한 출판편향을 고려하여 해당 메타연구의 결과가 과대 또는 과소 추정되지는 않았는지 확인하여야 한다.
시각적 확인(funnel plot)
STATA에서는 metafunnel 명령어를 제공하는데 앞에서 살펴본 대로 metan을 사용하여 통합효과크기를 먼저 산출한 후 이어서 분석하여야 한다. Table 1의 연속형 자료, 생존형 자료, 그리고 유병률 자료를 아래의 명령어를 사용하여 각각의 funnel plot을 나타내었다(Figure 5).
metafunnel _ES _seES, xtitle(Standard mean difference; Hedges’s g) ytitle(Standard error of SMD)
metafunnel lnhr selnhr, xtitle(Log hazard ratio) ytitle(Standard error of log HR)
metafunnel _ES _seES, xtitle(Resistance of antibiotics) ytitle (Standard error)
metafunnel 명령어에 효과크기(_ES/lnhr)와 표준오차(_seES/selnhr)를 순서대로 넣어준다. 쉼표 뒤의 xtitle과 ytitle은 각각의 이름을 지정한 것이다.
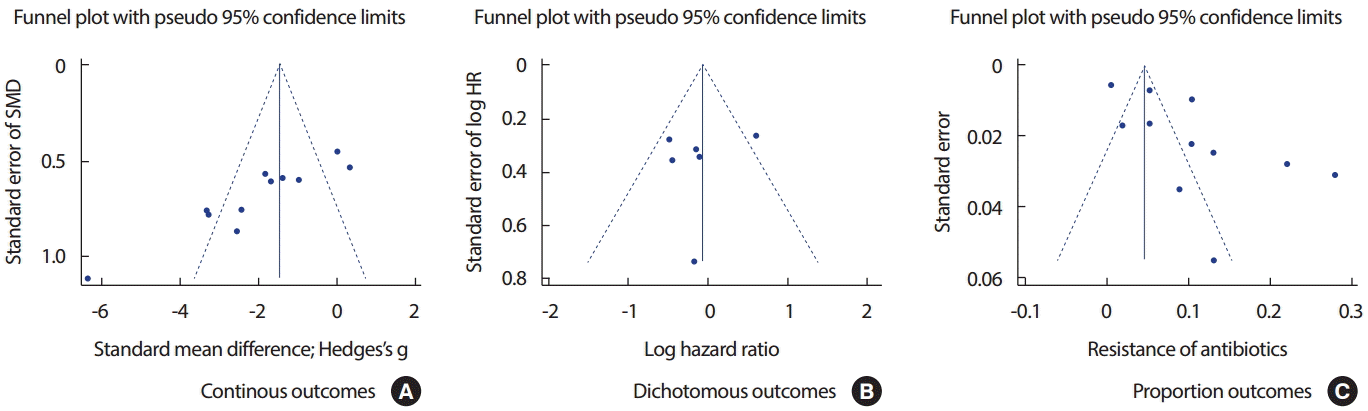
Funnel plot의 Y축은 표본크기(표준오차)를 X축은 효과크기를 제시한다. 일반적으로 작은 규모의 연구들은 아래쪽에 넓게 분포되며 큰 규모의 연구들은 깔때기 안 상단에 좁게 분포된다. 따라서 깔때기 안 상단에 좌우대칭으로 골고루 분포되어 있다면 출판편향은 적다고 판단할 수 있다.
연속형 자료의 경우(Figure 5A) X축의 중앙 SMD를 기준으로 깔때기 바깥 좌측으로 3개, 우측으로 2개의 연구가, 깔때기 안 좌측으로 4개, 우측으로 2개의 연구가 분포한다. 시각적으로 판단하기에 출판편향이 있을 것으로 판단된다. 생존형 자료의 경우(Figure 5B) X축의 중앙 ln hazard ratio를 기준으로 깔때기 바깥 우측으로 1개의 연구가, 깔때기 안 좌측으로 5개의 연구가 모두 몰려있어 이 또한 좋은 분포가 아니다. 유병률 자료의 경우(Figure 5C) X축의 중앙 Resistance of antibiotics를 기준으로 깔때기 바깥 좌측으로 1개, 우측으로 5개의 연구가, 깔때기 안 좌측으로 1개, 우측으로 4개의 연구가 모두 몰려있어 대칭성을 나타내지 못하고 있다.
통계적 검정
출판편향을 통계적으로 검정하는 일반적인 방법은 Egger’s linear regression method test [19], Begg and Mazumdar’s rank correlation test [20], 그리고 Orwin’s failsafe N이 있다. Egger’s linear regression method test가 Begg and Mazumdar’s rank correlation test보다 효과크기의 실제 추정치를 더 정확히 추정한다고 보고하고 있으며 Failsafe N은 통계적 방법에만 치중하고 있어 실제적인 임상적 유의성을 판단하지 못하여 사용을 권고하지 않는다[21]. 그러나 통계적 검정은 출판편향의 영향보다는 연구의 수가 적을 경우(small study effect) 이를 정확히 검정하지 못하므로 Cochrane에서는 권고하지 않는다.
Begg and Mazumdar’s rank correlation test
개별 연구들의 표준화된 효과크기와 표준오차와의 상관관계를 보정된 순위상관(rank correlation)으로 검정한다. 순위상관 검정이 유의하지 않다면 출판편향이 없음을 나타낸다.
STATA에서는 metabias 명령어를 제공하는데 앞에서 살펴본 대로 metan을 사용하여 통합효과크기를 먼저 산출한 후 이어서 분석하여야 한다.
Table 1의 연속형 자료와 유병률 자료를 아래의 명령어를 사용하여 Begg and Mazumdar’s rank correlation test를 실시하였다.
metabias _ES _seES, begg
연속형 자료의 경우 continuity를 보정한 Z는 2.96, p값이 0.003으로 출판편향이 있음을 확인할 수 있으며 유병률 자료의 경우 continuity를 보정한 Z는 1.40, p값이 0.161로 출판편향이 있음을 증명할 수 없다.
Table 1의 생존형 자료를 아래의 명령어를 사용하여 분석한 결과 continuity를 보정한 Z는 0.00, p값이 1.000으로 출판편향이 있음을 증명할 수 없다.
metabias lnhr selnhr, begg
Egger’s linear regression method test
중재효과의 표준오차에 대한 개별 연구들의 효과크기 관계를 회귀식으로 나타낸 것으로 귀무가설은 회귀식의 초깃값(intercept)은 우연에 의한 결과로서 출판편향이 있음을 증명할 수 없다는 것이다[19]. STATA에서는 metabias 명령어를 제공하는데 metan을 사용하여 통합효과크기를 먼저 산출한 후 이어서 분석하여야 한다.
Table 1의 연속형 자료와 유병률 자료를 아래의 명령어를 사용하여 Egger’s linear regression method test를 실시한 결과를 Table 4에 나타내었다.
metabias _ES _seES, egger
연속형 자료의 경우 전체 11개의 연구를 사용하였고 bias항목의 Coef.가 -9.23으로 초깃값(intercept)을 나타내며 해당 p값이 0.001로서 귀무가설을 기각하여 출판편향이 있음을 확인할 수 있다. 유병률 자료의 경우 전체 11개의 연구를 사용하였고 bias항목의 Coef.가 -5.18로 초깃값(intercept)을 나타내며 해당 p값이 0.019로서 귀무가설을 기각하여 출판편향이 있음을 확인할 수 있다.
Table 1의 생존형 자료를 아래의 명령어를 사용하여 분석한 결과 전체 6개의 연구를 사용하였고 bias항목의 Coef.가 -1.23으로 초깃값(intercept)을 나타내며 해당 p값이 0.636로서 귀무가설을 기각하지 않아 출판편향이 있음을 증명할 수 없다.
metabias lnhr selnhr, egger
출판편향추정치 보정: trim and fill
Funnel plot상에서 대상연구들이 비대칭성을 보인다면 효과크기는 한쪽으로 편향될 가능성이 있다. 따라서 민감도분석(sensitivity analysis)의 일환으로 대칭성이 충족된 상태에서 보정된 효과크기를 확인하는 것이 trim and fill이다.
Trim and fill은 메타분석에 있어서 출판편향을 비모수적 방법으로 효과크기 추정치를 보정한다[22]. 방법은 Funnel plot상에서 비대칭성을 나타내는 연구들을 절삭(trim)하여 남아있는 대칭성을 나타내는 연구들의 효과크기를 계산한 후 최초 절삭된 연구들과 대비하여 대칭을 나타내는 가상의 연구들을 채워(fill) 넣는다. 그런 다음 기존 연구들과 가상의 연구들을 모두 포함하여 통합효과크기를 계산하게 되면 시각적으로 비대칭성을 극복한 상태에서 보정된 통합효과크기를 추정할 수 있다. STATA에서는 metatrim 명령어를 제공하는데 metan을 사용하여 먼저 통합효과크기를 산출한 후 이어서 metatrim 명령어에 효과크기(_ES/lnhr)와 표준오차(_seES/selnhr)를 순서대로 넣어준다.
연속형 자료와 유병률 자료의 명령어는 동일하며 아래와 같다.
metatrim _ES _seES, reffect funnel
생존형 자료의 명령어는 아래와 같다.
metatrim lnhr selnhr, reffect eform funnel
옵션들 중 reffect는 변량효과 모형을 사용하는 것 ― 고정효과 모형이 default임 ― 이고, funnel은 채워지는 가상의 연구들을 funnel plot 상에 표시하라는 것이다.
본 연구의 예제로 주어진 3가지 유형(연속형, 생존형, 그리고 유병률)의 자료는 trim and fill에 따른 통합효과크기의 변동이 없었다. 하지만 실행방법을 보여주고자 Table 1의 유병률 자료를 고정효과모형으로 분석한 후 trim and fill을 실시하여 Figure 6에 나타내었다. Figure 5C와 비교해서 보면 전체 11개의 연구들 중 우측으로 치우친 5개를 절삭한 후 이에 대응하는 가상의 연구를 좌측에 5개를 추가하여 전체 16개의 연구들로 보정된 통합효과크기를 계산하였다. 최초 메타분석을 실시했을 때 고정효과모형의 값은 0.047 (95% CI: 0.040, 0.054)이었지만 trim and fill에 따른 보정된 값은 0.037 (95% CI: 0.030, 0.043)로 감소하였다.
결론 및 제언
본 연구는 통계학을 전공하지 않은 일반 연구자들도 쉽게 수행할 수 있도록 메타분석의 실질적 수행방법에 집중하고 통계학의 이론적 접근은 최소화하고자 노력하였다. 하지만 본 연구는 STATA 프로그램으로 메타분석을 수행하는 방법만을 정리한 것으로서 메타분석에 대한 심도 있는 이론적 접근에는 미치지 못하였다. 따라서 이를 본인의 연구로 올바르게 해석하기 위해서는 전문가 의견 청취 또한 소홀히 하여서는 안 될 것이다. 지금까지 살펴본 중재 메타분석 외에도 진단검사 메타분석(diagnostic test accuracy meta-analysis) [23] 방법도 STATA를 이용하여 쉽게 접근할 수 있으니 참고하기 바라며 이를 통하여 많은 국내 연구자들이 보다 쉽게 메타분석을 수행할 수 있게 되어 관련 연구들이 활성화되기를 바란다.