Wide & Deep Learning Model을 이용한 노인의 우울증 예측
Abstract
Objectives
This study aims to suggest a depression prediction model using variables indirectly related to depression, which helps determine whether the target is depressed.
Methods
This study using Korea Institute for Health and Social Affairs (KIHSA)'s 2011, 2014, 2017 National Survey of Older Koreans, and the total number of subjects of the study is 30,571 elderly people 65 years of age or older.
Results
The analysis way is deep learning especially Wide & Deep Learning model that separately learns simple data and complex data. The dependent variable is depression, and the independent variable is a total of 30 variables related to personal attributes, economic status, human relationships, health status, health behavior, and life satisfaction. As a result of the main study, all the independent variables used were found to be correlated with depression, performance of Wide & Deep model is 77.9% accuracy, 65.7% recall, 73.8% precision, 85.5% specificity, 69.5% F1-score, 85.3% AUROC, 90.0% AUPRC.
Conclusions
It is expected that it will be helpful for the welfare of the elderly by searching for depressed patients at a lower cost and searching for potential depressed patients who want to hide their depression.
Key words: Deep learning, Depression, Older, National Survey of Older Koreans
서 론
한국은 65세 이상 고 연령층이 2020년 15.7%, 2025년 20.3%, 2060년 43.9%로 예상되는 고령화가 급속도로 진행되는 나라로, 2025년을 기점으로 초고령 사회에 진입하고[ 1], 2050년 세계에서 2번째로 고령 인구(65세 이상 인구)의 비율이 높은 국가가 될 것으로 예측된다[ 2]. 고령화는 신체적 질병, 배우자의 사망, 자발적·강제적 노동시장 배제로 인한 경제력 악화, 사회로부터의 고립을 자연스럽게 발생시키고, 이와 같은 개인이 대처하기 힘든 상황은 당사자에게 심각한 수준의 스트레스를 작용하여 고령자 계층의 우울증 발생을 높이게 된다[ 3]. 빠른 고령화 속도와 고령화로 인한 우울증의 자연스러운 발생에 발맞춰 한국의 보건 관련 정책은 고령자의 신체적, 경제적 상태뿐만 아니라 정신적 건강상태에도 초점을 맞춰 진행되어야 할 것이다. 우울증은 단순하게 우울한 기분이 오랜 기간 동안 유지되는 상태를 뛰어넘어, 우울증 환자 본인의 생명에도 부정적인 영향을 미칠 위험이 있다. 미국 국립정신건강학회(National Institute of Mental Health)에 따르면, 우울증을 포함한 정신 질환은 자살의 주요 위험인자로, 자살자 가운데 90% 이상이 정신 질환을 보유하고 있으며, 우울증 환자는 충동조절장애, 자살 시도 혹은 자살로 인한 사망자와 동일하게 세로토닌(Serotonin) 저하가 관찰된다고 하였다[ 4]. 또한, 자살 기도를 1회 실시한 경우, 주요우울장애를 경험할 확률이 일반인에 비해 6.5배 높고, 2번 이상 자살 기도를 한 경우 7.9배 우울장애를 경험할 확률이 높다[ 5]는 연구를 볼 때, 우울증을 가지고 있는 대상을 빠르게 찾아내어, 표적 조사를 할 필요가 있는 것으로 보인다. 그러나 우울증과 같은 민감한 변수는 대상자가 자신에게 피해가 발생할 것을 염려하고, 응답을 회피하거나, 음성을 응답할 위험이 존재하며, 이를 막기 위해선 연구 대상자에게 해당 도구로 인한 피해가 없음을 교육해야 하고, 척도를 작성하는 당사자 역시, 해당 도구에 대한 적절한 수준의 교육이 이루어져야 한다. 본 연구에서는 선행연구[ 6– 13]를 통해 우울증에 영향을 미치는 것으로 알려진 변수들을 선정하고, 고령자의 우울증을 평가하는데 널리 사용되는 단축형 노인우울척도(Short form of Geriatric Depression Scale, SGDS) [ 14]를 이용해 평가한 대상의 우울증 여부를 예측할 수 있는 모델을 제안하고자 한다.
연구 방법
본 연구는 Figure 1과 같은 과정을 통해 진행되었으며, 크게 변수 선정, 데이터 수집 및 전처리, 데이터셋 생성, 모델 생성 및 최적화, 최적화된 모델 성능 평가로 진행되었다. 데이터 전처리 및 분석은 Python 3.6을 사용하여 진행하였으며, 사용된 주요 라이브러리와 버전은 다음과 같다.
- pandas (1.1.3), numpy (1.19.2), matplotlib (3.3.2), sklearn (1.5.2), tensorflow (2.4.0), tensorflow-gpu (2.4.0)
Figure 1.
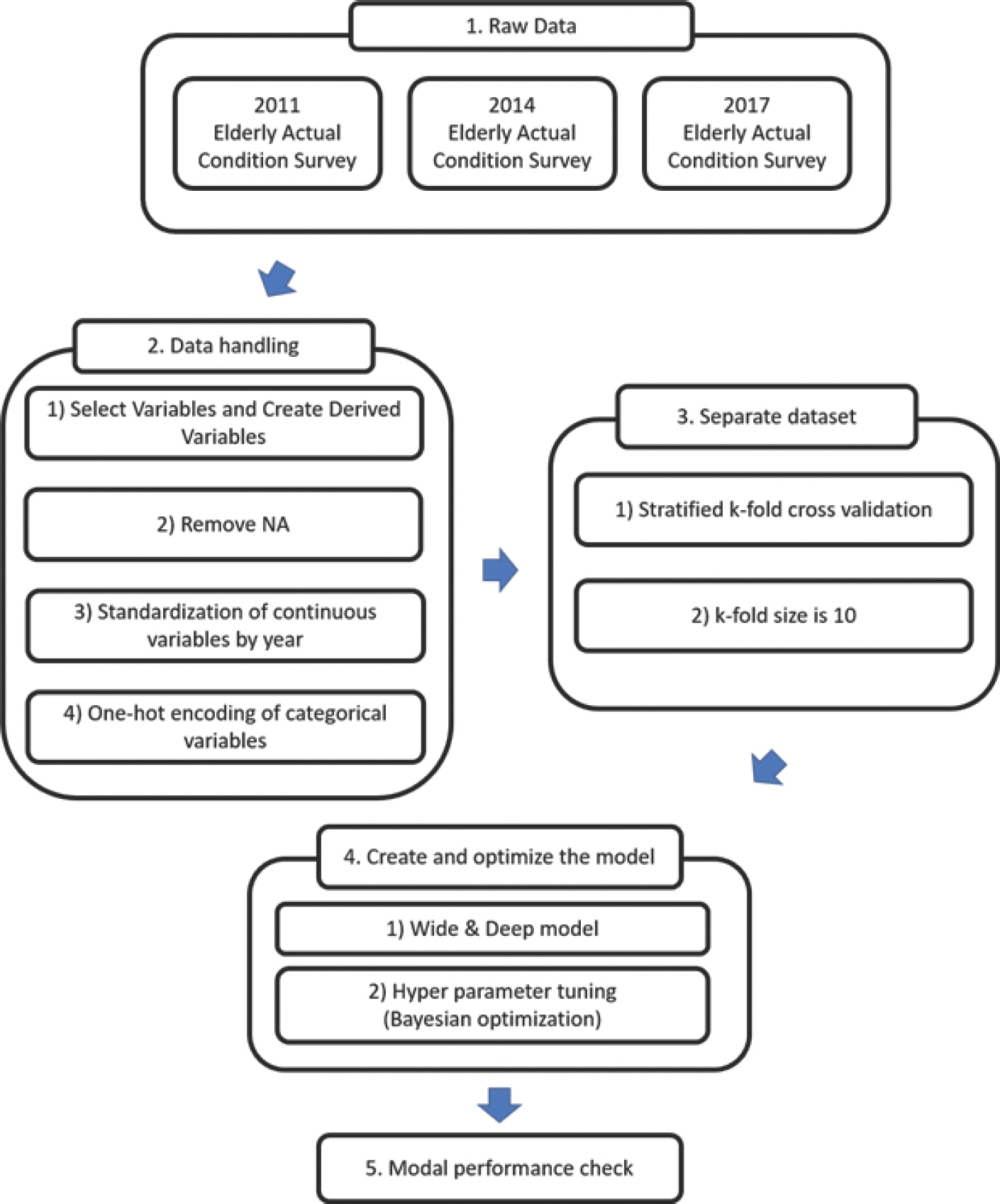
학습은 GPU를 사용하여 진행하였다. 학습에 사용된 GPU는 Nvidia RTX 3080 mobile이고, 사용된 CUDA 버전은 11.0, cuDNN은 8.0.5이다.
변수선정
선행연구에서 제시된 노인의 우울증에 영향을 미치는 요인은 성별, 교육 수준, 배우자 유무, 신체적 건강상태, 생활 수준, ADL, IADL, 여가활동 및 생활만족도, 가족관계 및 사회 관계 만족도, 주관적 건강상태, 삶의 질 등이 나타났다[ 6– 8]. 각각의 인자들은 단독으로도 우울증에 영향을 주는 것으로도 볼 수 있으나, 나아가 서로 영향을 주고받는 상호관계를 통해 우울증에 영향을 줄 가능성이 있다. 우울증에 영향을 미치는 요인 중 노인의 주관적 건강상태는 신체적, 생리적, 심리적, 사회적 측면에 대한 포괄적인 평가를 내려 의학적인 방법으로 측정할 수 없는 건강상태에 대한 개인적인 견해를 보여주는 것으로[ 9], 우울증을 직접 표현하는 변수는 아니나, 간접적으로 우울증이라는 증상을 만들어내는 다양한 요인들을 표현하는 것으로 볼 수 있다. 본 연구에서는 주관적 건강상태를 구성하는 신체적, 생리적, 심리적, 사회적 측면을 보다 세부적으로 표현한 “현재 활동 중인 사회 집단 수”, 시력, 청력, 씹기의 불편한 정도인 “일상생활 불편한 정도”, 운동 능력을 나타내는 정도인 “동작 수행이 어려운 정도”, 일상생활 동작 중 식사, 배설, 목욕과 같은 기본적인 동작의 수준을 나타내는 “ ADL”, ADL보다 복잡한 가사, 외출, 금전관리 등과 같은 응용동작의 수준을 나타내는 “ IADL”, “영양관리 상태 총점”을 사용하여, 주관적 건강상태라는 포괄적인 개념을 보다 세분화하여 바라본다면, 우울증 심각도의 숨겨진 패턴을 찾아내는 데 더욱 긍정적으로 작동할 것으로 보인다.
주관적 건강상태 인식에 영향을 미치는 요인은 성별, 연령, 경제적 상태, 결혼 상태, 학력, 직업 유무, 인지된 질병 및 건강형태에 영향을 받는다고 하였다[ 10, 11]. 다른 선행연구를 보면, 흡연, 알코올 섭취 등과 같은 생활양식 등이 주관적 건강상태 인식에 영향을 미친다고 하였다[ 12]. 이를 보면 선행연구에서 이야기한 우울증에 영향을 주는 요인과 주관적 건강상태 인식에 대해 영향을 미치는 요인이 상당히 유사한 것을 볼 수 있다. 이는 주관적 건강상태라는 개념이 다른 변수들의 매개변수로써 작용하는 것으로 보인다. 노인의 건강상태를 측정하는 방법은 크게 두 가지로, 하나는 신체적 건강스펙트럼(physical health spectrum)에 따라 건강 수준을 측정하는 것이며, 다른 하나는 본인 스스로 자신의 건강을 “좋다” 혹은 “나쁘다”고 판단하는 것이다. 이는 건강의 모든 영역을 포함하고 질병보다 안녕(wellbeing)을 강조하는 긍정적인 측정방식이므로, 건강증진 측면에서 장점이 있으며, 임상에서 얻어진 지표보다 스스로 평가한 건강상태가 오히려 신뢰할 수 있다고 하였다[ 13].
데이터 수집 및 전처리
데이터는 한국보건사회연구원의 노인실태조사를 사용하였으며 이 중 연구 대상자들이 서로 독립적인 2011, 2014, 2017년 데이터를 수집하였다. 변수 선정은 앞서 우울증에 영향을 미치는 요인으로 밝혀진 선행연구들과 각 데이터에 공통으로 존재하는 변수들을 위주로 추출하였다. 선별한 변수는 다음과 같다.
- 현재 활동 중인 사회 집단 수, 체질량지수, 주관적 건강상태, 시력·청력·저작 불편한 정도, 근력 상태, ADL 총점, IADL 총점, 인지기능 총점, 영양관리 총점, 삶의 만족도, 우울증 여부 등.
해당 데이터에서 우울증 여부는 단축형 노인우울척도[ 14]를 사용하였으며, 해당 도구에서 총점이 6점 이상인 경우 우울증상이 있는 것으로 판단하므로, 6점을 우울증 여부의 기준으로 사용하였다. 연도별 결측값은 2011년 10,996건 중 4.2%인 461건, 2014년 10,447건 중 3.2%인 332건, 2017년은 10,298건 중 3.7%인 377건으로 나타났다. Graham [ 15]는 결측값이 데이터에서 차지하는 비중이 5% 이하인 경우, 특별한 결측치 보정 없이 분석이 가능하다고 하였으므로[ 15], 이를 근거로 결측값을 일괄 제거하는 완전 제거법(Listwise deletion)을 실시하였다. 결측값을 제외한 연구 대상자 수는 2011년 10,535명, 2014년 10,115명, 2017년 9,921명으로 총 30,571명이다. 데이터의 텐서(tensor) 변환은 범주형 척도와 연속형 척도를 분리하여 실시하였다. 범주형 척도는 원-핫 벡터(one-hot vector)로 워드 임베딩(word embedding)하였으며, 연속형 척도는 훈련 데이터셋(train dataset), 시험 데이터셋(test dataset) 분리 후, 훈련 데이터셋의 연속형 변수의 최댓값, 최솟값 추출 후 최소-최대 정규화(min-max scailing)하였다.
데이터셋 생성
본 연구에서 사용할 데이터의 크기는 30,571명으로 매우 작아, 훈련 데이터셋, 검증 데이터셋(validation dataset), 시험 데이터셋이 우연히 매우 유사하여 모델의 성능이 좋게 나오거나, 반대로 나쁘게 나올 수 있으므로, Ron [ 16]이 다양한 데이터셋을 통해 테스트하여 얻어낸 결과에 따라, k=10인 10-겹 교차 검증을 실시하였다. 추가로 Label의 Class의 비율이 많이 차이가 나므로, 단순한 k-fold cross validation이 아닌 년도별 Class의 비율에 따라 데이터를 나누는 Stratified k-fold cross validation을 실시하였다( Figure 2).
Figure 2.
k-fold cross validationdataset (k=10). 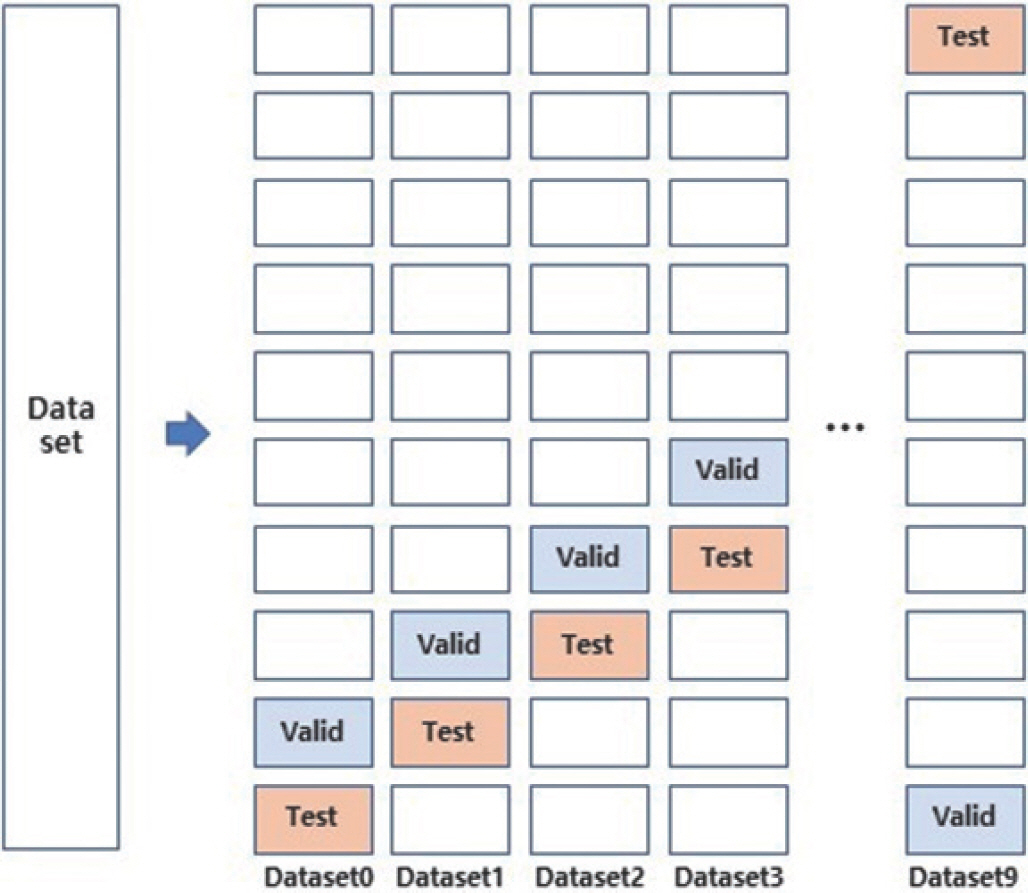
데이터 분할은 10개로 진행하였으며(k=10), 10개의 Fold는 Label의 Class의 비율에 맞춰 분할하였다. 10개의 Fold는 각각 검증 데이터셋, 시험 데이터 셋으로 순차적으로 할당하여 학습에 사용하였다.
모델 생성 및 최적화
사용한 딥러닝 모델은 2016년 구글(Google)에서 발표하였으며, 구글 플레이스토어(Google playstore)의 추천 알고리즘으로 사용되었던 Wide & Deep Learning model [ 17]을 사용하였다( Figure 3).
Figure 3.
Wide & Deep learning model. 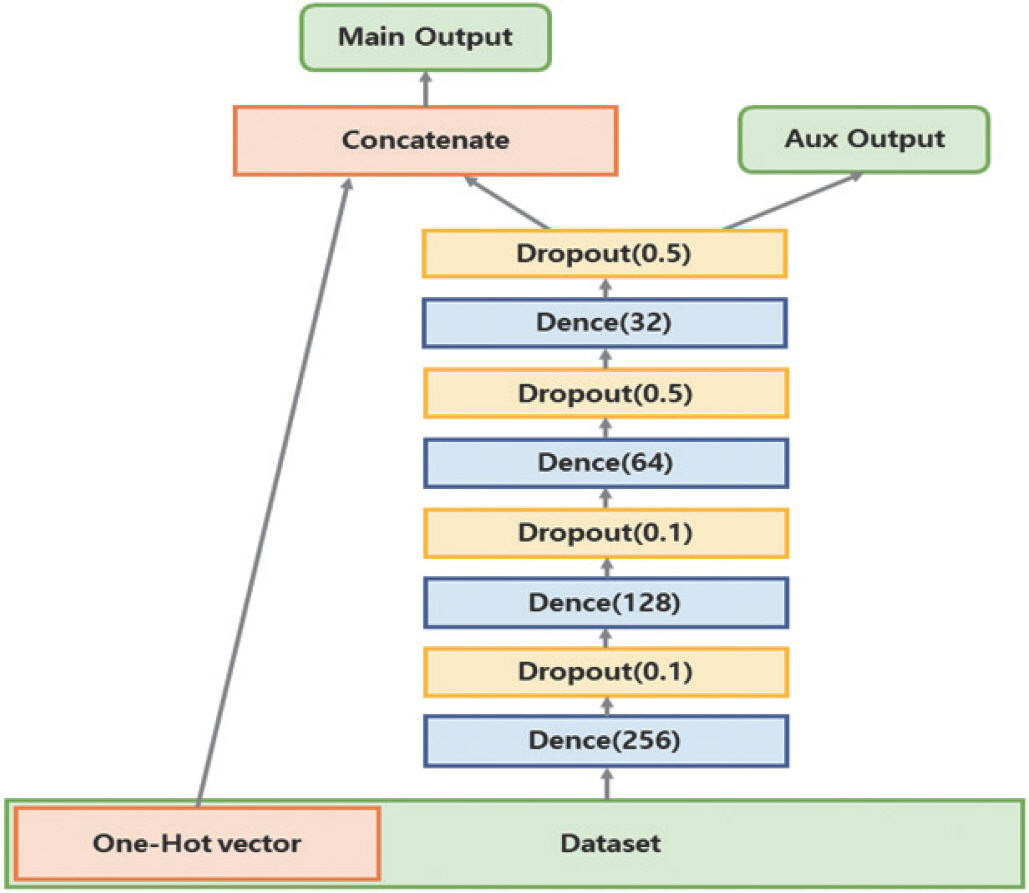
일반적인 딥러닝 모델에 간단한 패턴을 가진 데이터를 학습시키는 경우, 많은 층을 통과하면서 그 패턴이 왜곡될 위험이 존재하나, Wide & Deep Learning model은 Wide model과 Deep model로 나눠 복잡한 패턴의 데이터와 단순한 패턴의 데이터를 분리하여 동시에 학습시킬 수 있다.
본 연구에서는 범주형 척도로 만든 희소 벡터인 원-핫 벡터를 단순한 패턴으로 판단하고, 연속형 데이터로 만들어진 텐서와 분리하여, 연속형 데이터는 Deep model에 범주형 데이터로 만들어진 희소 텐서(sparse tensor)는 Wide model에 학습시켰다. 추가로, 보조출력부(auxil-iary output)을 만들어, Deep model과 Wide model의 손실값의 비율을 조정(0.9:0.1)하여, 모델이 수렴하는 속도를 간접적으로 조정하였다.
학습 시, Epochs는 1,000으로 설정하였으나, 모델이 빠르게 최적화되어, 설정한 Epochs까지 학습 시, 학습 데이터셋에 과적합이 발생하는 문제를 피하고자 조기종료규제를 사용하였으며, Mini batch는 512로 Hoffer et al. [ 18]의 연구를 근거로, VRAM을 초과하지 않는 선의 최대 크기로 설정하였다. 파라미터 최적화에 사용된 경사하강법(gradient descent)은 Momentum의 관성과 RMSProp (root mean sqaure propagation)의 지나가 본 곳을 좁게 이동하는 두 장점을 합친 Adam을 사용하였다. 하이퍼 파라미터 튜닝은 베이지안 최적화(Bayesian optimization)을 사용하였다. 해당 방법은 총 100번의 탐색을 진행하였으며, 하이퍼 파라미터 중 학습률은 0.001-0.00001 사이로, Beta1과 Beta2는 0.85-0.99 사이의 값 중 10개 데이터셋의 area under the precision-recall curve (AUPRC)를 최대로 하는 값을 탐색하였다.
모델 성능 평가
모델 성능 평가에는 혼동행렬 사용하였으며, 민감도, 정밀도, 특이도, 정확도, F1-score, area under the receiver operating characteristic (AUROC), AUPRC를 교차하여 보았다. 해당 데이터의 Label인 우울증 여부의 Class별 비율은 정상(0.62), 우울증(0.38)로 비교적 불균형한 상태이므로, AUROC보다 AUPRC에 중점을 두었고, 양성(우울증) 예측 능력이 음성(정상) 예측 능력보다 중요하므로, 민감도와 정밀도, 그로부터 파생되는 F1-score에 중점을 두었다.
연구 결과
우울증 예측에 사용된 독립변수에 대하여, 각 변수를 구성하는 집단의 빈도와 우울증의 연관성을 보여주는 교차분석 결과는 Tables 1-6과 같다.
Table 1.
Association between demographic variables and depression
|
Variables |
Class |
Depression (0-5) |
Depression (6-15) |
χ2
|
p
|
|
n |
% |
n |
% |
|
Sex |
Male |
8,417 |
27.5 |
3,963 |
13.0 |
353.13 |
0.000 |
|
Female |
10,430 |
34.1 |
7,761 |
25.4 |
|
|
|
Age (y) |
65-69 |
5,644 |
18.5 |
2,213 |
7.2 |
768.18 |
0.000 |
|
70-75 |
5,797 |
19.0 |
3,217 |
10.5 |
|
|
|
75-80 |
4,407 |
14.4 |
3,361 |
11.0 |
|
|
|
80-85 |
2,149 |
7.0 |
2,004 |
6.6 |
|
|
|
≥85 |
850 |
2.8 |
929 |
3.0 |
|
|
|
Marital status |
Have a spouse |
12,776 |
41.8 |
6,220 |
20.3 |
672.18 |
0.000 |
|
Bereavement |
5,541 |
18.1 |
4,980 |
16.3 |
|
|
|
Divorce |
358 |
1.2 |
367 |
1.2 |
|
|
|
Separation |
119 |
0.4 |
97 |
0.3 |
|
|
|
Single |
53 |
0.2 |
60 |
0.2 |
|
|
|
Level of education |
None (cant read) |
1,283 |
4.2 |
1,842 |
6.0 |
1,591.43 |
0.000 |
|
None (can read) |
3,389 |
11.1 |
3,230 |
10.6 |
|
|
|
Elementary school graduation |
6,678 |
21.8 |
4,019 |
13.1 |
|
|
|
Middle School graduation |
2,929 |
9.6 |
1,197 |
3.9 |
|
|
|
High school graduation |
3,087 |
10.1 |
1,109 |
3.6 |
|
|
|
Graduated from junior college |
235 |
0.8 |
71 |
0.2 |
|
|
|
University graduate or higher |
1,246 |
4.1 |
256 |
0.8 |
|
|
Table 2.
Association between economic conditions and depression
|
Variables |
Class1
|
Depression (0-5) |
Depression (6-15) |
χ2
|
p
|
|
n |
% |
n |
% |
|
Total income of subject |
>100 |
559 |
1.8 |
323 |
1.1 |
616.65 |
0.000 |
|
100->200 |
1,282 |
4.2 |
1,098 |
3.6 |
|
|
|
200->300 |
1,496 |
4.9 |
1,269 |
4.2 |
|
|
|
300->400 |
1,538 |
5.0 |
1,428 |
4.7 |
|
|
|
400->500 |
1,551 |
5.1 |
1,486 |
4.9 |
|
|
|
≥500 |
12,421 |
40.6 |
6,120 |
20.0 |
|
|
|
Household income |
>100 |
2 |
0.0 |
3 |
0.0 |
503.93 |
0.000 |
|
100->200 |
6 |
0.0 |
37 |
0.1 |
|
|
|
200->300 |
66 |
0.2 |
112 |
0.4 |
|
|
|
300->400 |
165 |
0.5 |
314 |
1.0 |
|
|
|
400->500 |
384 |
1.3 |
626 |
2.0 |
|
|
|
≥500 |
18,224 |
59.6 |
10,632 |
34.8 |
|
|
|
Average monthly consumption expenditure in the previous year |
>100 |
6,560 |
21.5 |
6,302 |
20.6 |
1,125.75 |
0.000 |
|
100->200 |
7,427 |
24.3 |
3,586 |
11.7 |
|
|
|
200->300 |
2,906 |
9.5 |
1,187 |
3.9 |
|
|
|
300->400 |
1,251 |
4.1 |
437 |
1.4 |
|
|
|
400->500 |
434 |
1.4 |
119 |
0.4 |
|
|
|
≥500 |
269 |
0.9 |
93 |
0.3 |
|
|
Table 3.
Association between human relationship and depression
|
Variables |
Class |
Depression (0-5) |
Depression (6-15) |
χ2
|
p
|
|
n |
% |
n |
% |
|
Total number of household members |
1 |
3,927 |
12.8 |
3,668 |
12.0 |
459.71 |
0.000 |
|
2 |
10,883 |
35.6 |
5,566 |
18.2 |
|
|
|
3 |
2,123 |
6.9 |
1,325 |
4.3 |
|
|
|
≥4 |
1,914 |
6.3 |
1,165 |
3.8 |
|
|
|
Number of children living together |
0 |
14,508 |
47.5 |
8,824 |
28.9 |
17.33 |
0.001 |
|
1 |
3,895 |
12.7 |
2,651 |
8.7 |
|
|
|
2 |
406 |
1.3 |
229 |
0.7 |
|
|
|
≥3 |
38 |
0.1 |
20 |
0.1 |
|
|
|
Number of active social groups |
0 |
3,394 |
11.1 |
4,603 |
15.1 |
2,218.09 |
0.000 |
|
1 |
6,363 |
20.8 |
4,021 |
13.2 |
|
|
|
2 |
5,284 |
17.3 |
2,139 |
7.0 |
|
|
|
3 |
2,627 |
8.6 |
729 |
2.4 |
|
|
|
4 |
867 |
2.8 |
192 |
0.6 |
|
|
|
≥5 |
312 |
1.0 |
40 |
0.1 |
|
|
|
Annual number of visits by non-cohabiting offspring |
No offspring |
560 |
1.8 |
590 |
1.9 |
426.49 |
0.000 |
|
Rarely do |
169 |
0.6 |
273 |
0.9 |
|
|
|
1-2 times a year |
1,144 |
3.7 |
1,134 |
3.7 |
|
|
|
1-2 times every 3 months |
3,501 |
11.5 |
2,424 |
7.9 |
|
|
|
1-2 times every 1 month |
6,392 |
20.9 |
3,520 |
11.5 |
|
|
|
1 time every 1 week |
3,517 |
11.5 |
1,933 |
6.3 |
|
|
|
2-3 times evey 1 week |
1,725 |
5.6 |
968 |
3.2 |
|
|
|
Almost everyday |
1,839 |
6.0 |
882 |
2.9 |
|
|
|
Annual get in touch level of non-cohabiting offspring |
No offspring |
560 |
1.8 |
590 |
1.9 |
722.23 |
0.000 |
|
Rarely do |
132 |
0.4 |
280 |
0.9 |
|
|
|
1-2 times a year |
143 |
0.5 |
210 |
0.7 |
|
|
|
1-2 times every 3 months |
445 |
1.5 |
518 |
1.7 |
|
|
|
1-2 times every 1 month |
2,922 |
9.6 |
2,434 |
8.0 |
|
|
|
1 time every 1 week |
4,856 |
15.9 |
2,889 |
9.5 |
|
|
|
2-3 times evey 1 week |
5,105 |
16.7 |
2,719 |
8.9 |
|
|
|
Almost everyday |
4,684 |
15.3 |
2,084 |
6.8 |
|
|
Table 4.
Association between health condition and depression
|
Variables |
Class |
Depression (0-5) |
Depression (6-15) |
χ2
|
p
|
|
n |
% |
n |
% |
|
Total number of chronic diseases diagnosed by doctors |
0 |
2,474 |
8.1 |
492 |
1.6 |
1,854.46 |
0.000 |
|
1 |
4,105 |
13.4 |
1,344 |
4.4 |
|
|
|
2 |
4,629 |
15.1 |
2,426 |
7.9 |
|
|
|
≥3 |
7,639 |
25.0 |
7,462 |
24.4 |
|
|
|
Number of doctor-prescribed medications taken over 3 months |
0 |
3,755 |
12.3 |
1,132 |
3.7 |
1,230.79 |
0.000 |
|
1 |
3,385 |
11.1 |
1,316 |
4.3 |
|
|
|
2 |
3,238 |
10.6 |
1,740 |
5.7 |
|
|
|
≥3 |
8,469 |
27.7 |
7,536 |
24.7 |
|
|
|
BMI |
>18.5 |
686 |
2.2 |
789 |
2.6 |
196.54 |
0.000 |
|
18.5->23.0 |
7,614 |
24.9 |
4,988 |
16.3 |
|
|
|
23->25.0 |
5,111 |
16.7 |
2,738 |
9.0 |
|
|
|
≥25.0 |
5,436 |
17.8 |
3,209 |
10.5 |
|
|
|
ADL score |
0 |
18,357 |
60.0 |
10,366 |
33.9 |
1,025.39 |
0.000 |
|
≥1 |
490 |
1.6 |
1,358 |
4.4 |
|
|
|
IADL score |
0 |
16,748 |
54.8 |
8,266 |
27.0 |
1,636.54 |
0.000 |
|
≥1 |
2,099 |
6.9 |
3,458 |
11.3 |
|
|
|
Cognitive function score |
>25 |
7,766 |
25.4 |
7,274 |
23.8 |
1,254.91 |
0.000 |
|
≥25 |
11,081 |
36.2 |
4,450 |
14.6 |
|
|
|
Subjective health status |
Very bed |
368 |
1.2 |
1,460 |
4.8 |
5,546.82 |
0.000 |
|
Bed |
5,092 |
16.7 |
6,581 |
21.5 |
|
|
|
So so |
4,725 |
15.5 |
2,240 |
7.3 |
|
|
|
Good |
8,182 |
26.8 |
1,419 |
4.6 |
|
|
|
Very good |
480 |
1.6 |
24 |
0.1 |
|
|
|
Degree of discomfort in sight, hearing, and chewing |
0 |
7,685 |
25.1 |
2,140 |
7.0 |
2,468.94 |
0.000 |
|
1 |
6,021 |
19.7 |
3,557 |
11.6 |
|
|
|
2 |
3,307 |
10.8 |
3,158 |
10.3 |
|
|
|
≥3 |
1,834 |
6.0 |
2,869 |
9.4 |
|
|
|
Strength score |
0 |
4,974 |
16.3 |
726 |
2.4 |
3,204.36 |
0.000 |
|
1 |
3,047 |
10.0 |
882 |
2.9 |
|
|
|
2 |
1,344 |
4.4 |
552 |
1.8 |
|
|
|
≥3 |
9,482 |
31.0 |
9,564 |
31.3 |
|
|
Table 5.
Association between health behavior and depression
|
Variables |
Class |
Depression (0-5) |
Depression (6-15) |
χ2
|
p
|
|
n |
% |
n |
% |
|
Current smoking |
Smoking |
2,040 |
6.7 |
1,374 |
4.5 |
5.75 |
0.016 |
|
No smoking |
16,807 |
55.0 |
10,350 |
33.9 |
|
|
|
Drinking level |
No drinking in the past year |
12,869 |
42.1 |
9,183 |
30.0 |
391.57 |
0.000 |
|
Less than once a month |
796 |
2.6 |
421 |
1.4 |
|
|
|
Once a month |
765 |
2.5 |
315 |
1.0 |
|
|
|
2-4 times a month |
1,538 |
5.0 |
626 |
2.0 |
|
|
|
2-3 times a week |
1,307 |
4.3 |
458 |
1.5 |
|
|
|
4-6 times a week |
393 |
1.3 |
158 |
0.5 |
|
|
|
Everyday |
1,179 |
3.9 |
563 |
1.8 |
|
|
|
Whether regular exercise |
Exercise |
12,107 |
39.6 |
5,334 |
17.4 |
1,035.38 |
0.000 |
|
No exercise |
6,740 |
22.0 |
6,390 |
20.9 |
|
|
|
Level of nutrition management |
Good (0-2) |
11,524 |
37.7 |
3,527 |
11.5 |
3,996.90 |
0.000 |
|
Needs attention (3-5) |
5,624 |
18.4 |
4,141 |
13.5 |
|
|
|
Needs improvement (≥6) |
1,699 |
5.6 |
4,056 |
13.3 |
|
|
Table 6.
Association between life satisfaction and depression
|
Variables |
Class |
Depression (0-5) |
Depression (6-15) |
χ2
|
p
|
|
n |
% |
n |
% |
|
State of health |
Not satisfied at all |
423 |
1.4 |
1,896 |
6.2 |
6,455.97 |
0.000 |
|
Not satisfied |
4,762 |
15.6 |
6,387 |
20.9 |
|
|
|
So so |
5,093 |
16.7 |
2,160 |
7.1 |
|
|
|
Satisfaction |
7,986 |
26.1 |
1,246 |
4.1 |
|
|
|
Very satisfied |
583 |
1.9 |
35 |
0.1 |
|
|
|
State of the economy |
Not satisfied at all |
563 |
1.8 |
1,727 |
5.6 |
4,448.28 |
0.000 |
|
Not satisfied |
5,212 |
17.0 |
6,045 |
19.8 |
|
|
|
So so |
7,714 |
25.2 |
3,066 |
10.0 |
|
|
|
Satisfaction |
5,152 |
16.9 |
873 |
2.9 |
|
|
|
Very satisfied |
206 |
0.7 |
13 |
0.0 |
|
|
|
Spouse |
Not applicable |
6,081 |
19.9 |
5,506 |
18.0 |
1,646.03 |
0.000 |
|
Not satisfied at all |
45 |
0.1 |
90 |
0.3 |
|
|
|
Not satisfied |
426 |
1.4 |
629 |
2.1 |
|
|
|
So so |
2,463 |
8.1 |
2,061 |
6.7 |
|
|
|
Satisfaction |
8,873 |
29.0 |
3,195 |
10.5 |
|
|
|
Very satisfied |
959 |
3.1 |
243 |
0.8 |
|
|
|
Offspring relationship |
Not applicable |
276 |
0.9 |
356 |
1.2 |
2,273.08 |
0.000 |
|
Not satisfied at all |
103 |
0.3 |
295 |
1.0 |
|
|
|
Not satisfied |
502 |
1.6 |
1,084 |
3.5 |
|
|
|
So so |
2,464 |
8.1 |
3,126 |
10.2 |
|
|
|
Satisfaction |
13,800 |
45.1 |
6,391 |
20.9 |
|
|
|
Very satisfied |
1,702 |
5.6 |
472 |
1.5 |
|
|
|
Society/leisure/cultural activities |
Not satisfied at all |
276 |
0.9 |
787 |
2.6 |
3,456.47 |
0.000 |
|
Not satisfied |
2,605 |
8.5 |
3,869 |
12.7 |
|
|
|
So so |
6,153 |
20.1 |
4,415 |
14.4 |
|
|
|
Satisfaction |
8,921 |
29.2 |
2,531 |
8.3 |
|
|
|
Very satisfied |
892 |
2.9 |
122 |
0.4 |
|
|
베이지안 최적화 결과 산출된 하이퍼 파라미터는 학습률 0.00028867. Beta1 0.96357, Beta2 0.85.50으로 나왔으며, 모델 학습 과정에서 Epoch 의 변화에 따른 손실값과 정확도의 변화는 Figure 4와 같다. Figure 4를 보면, Val loss가 Loss보다 Epoch 15 부근에서 증가하는 모습을 보여주며, 해당 순간부터 모델이 훈련 데이터셋에 과적합될 위험이 증가하는 것을 볼 수 있다. 해당 모델은 조기종료 알고리즘을 적용하여, 해당 사건 발생 후, 30번을 추가로 학습하고도 이와 같은 경향이 지속될 때, 해당 Point의 파라미터를 최종 파라미터로 사용하고 학습을 정지하였다.
Figure 4.
Loss and accuracy accoding to epochs. 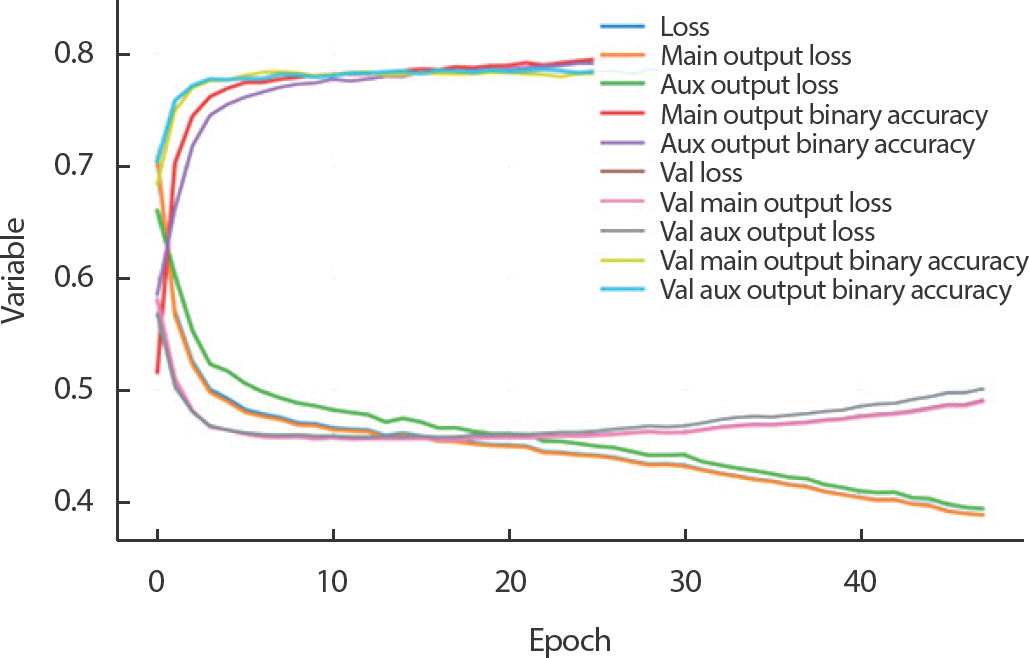
Threshold 변화에 따른 모델의 전반적인 분류 성능을 보여주는 ROC 커브(receiver operating characteristic curve)와 Precision-Recall 커브는 Figure 5와 같다. Dataset별 ROC 커브는 큰 편차가 없이 모여 있는 것을 볼 수 있으며, 곡선이 좌측 상단에 가까운 모습을 보여주긴 하나, 이상적인 수준으로 붙지 못하는 모습을 보여주고 있으며, Precision-Recall 커브 역시 데이터셋별 편차가 크진 않으나, 우상단의 모서리로부터 거리가 제법 있는 모습을 보여주고 있다. 이는 해당 모델을 통해 예측된 결과가 0과 1에 매우 근사한 상태가 아닌 그 사이 값이 많은 상태로, 모델이 명확하게 분류하지 못하는 대상이 상당수 있음을 보여준다.
Figure 5.
ROC curve and Precision-Recall curve. ROC, receiver operating characteristic. 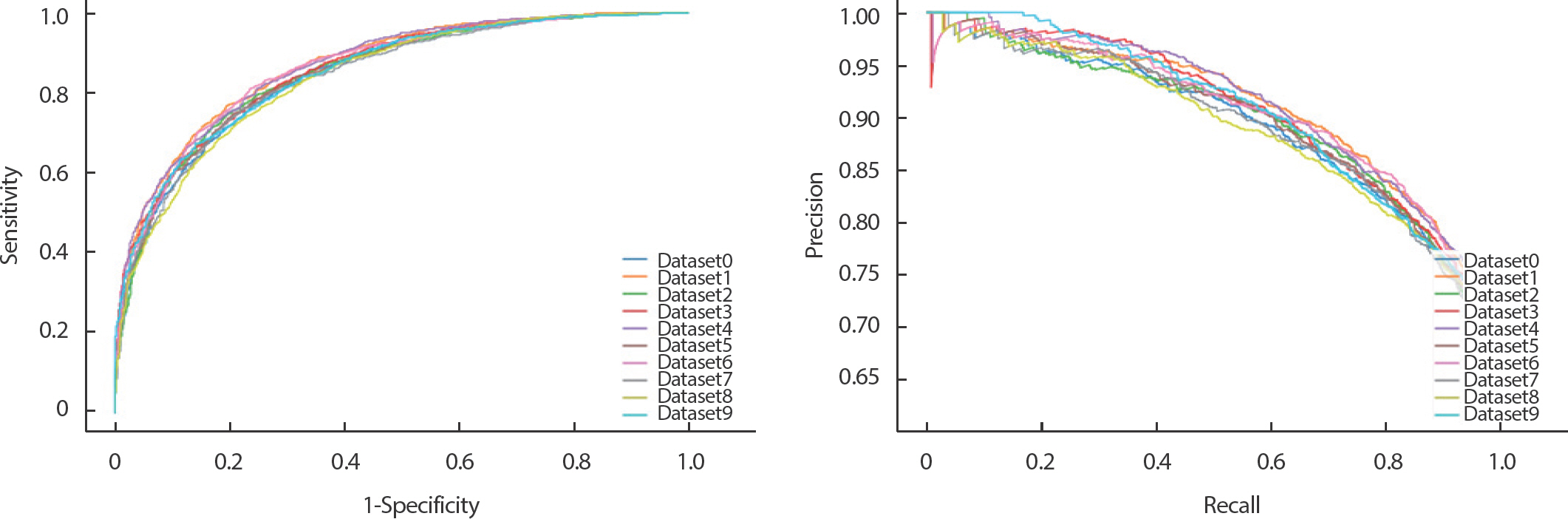
모델의 전반적인 성능은 Table 7에 정리되어 있다. 실제로 양성(우울증)인 대상을 양성으로 예측한 비율은 0.657이며, 양성으로 예측한 환자 중 실제로 양성인 사람의 비율은 0.739로 나타났다. 이 두 값의 조화 평균인 F1-score는 0.695로 해당 모델의 양성 예측 능력은 존재하긴 하나, 작은 실수도 큰 위협이 될 수 있는 임상에서 사용하기엔 아직 부족한 성능을 보여주었다. 모델의 정확도는 0.773으로 해당 모델의 예측 능력은 77.3%로 나타났다. 해당 모델의 분류 성능을 보여주는 AUROC 는 0.853으로, 해당 모델은 우수한 분류 성능을 보여주고 있다. 그러나 해당 모델은 “양성:음성=3.8:6.2”로 Label이 치우쳐져 있는 상태이므로, AUROC가 높게 나오기 쉬우므로, 양성 분류 능력만을 보여주는 AUPRC와 교차하여 평가해야 한다. AUPRC는 0.900으로, Baseline인 0.38의 2.37배로 나와 양성 분류 성능이 존재하는 것을 보여주었다.
Table 7.
Model performance by dataset
|
Dataset |
Sensitivity |
Precision |
Specificity |
Accuracy |
F1-score |
AUROC |
AUPRC |
|
Dataset0 |
0.658 |
0.739 |
0.855 |
0.780 |
0.696 |
0.845 |
0.892 |
|
Dataset1 |
0.628 |
0.782 |
0.891 |
0.790 |
0.697 |
0.867 |
0.909 |
|
Dataset2 |
0.680 |
0.721 |
0.836 |
0.776 |
0.700 |
0.849 |
0.896 |
|
Dataset3 |
0.666 |
0.733 |
0.849 |
0.779 |
0.698 |
0.856 |
0.904 |
|
Dataset4 |
0.643 |
0.765 |
0.878 |
0.787 |
0.699 |
0.867 |
0.912 |
|
Dataset5 |
0.664 |
0.726 |
0.845 |
0.775 |
0.694 |
0.849 |
0.898 |
|
Dataset6 |
0.696 |
0.746 |
0.853 |
0.793 |
0.720 |
0.860 |
0.904 |
|
Dataset7 |
0.632 |
0.721 |
0.848 |
0.765 |
0.674 |
0.842 |
0.892 |
|
Dataset8 |
0.633 |
0.729 |
0.854 |
0.769 |
0.678 |
0.840 |
0.889 |
|
Dataset9 |
0.666 |
0.722 |
0.840 |
0.773 |
0.693 |
0.851 |
0.904 |
|
Mean |
0.657 |
0.738 |
0.855 |
0.779 |
0.695 |
0.853 |
0.900 |
고찰 및 결론
본 연구는 직접적으로 우울증을 나타내는 변수를 사용하지 않고 우울증을 예측할 수 있는 보조 도구를 제시해보고자 실시하였다. 이와 유사한 목적으로 실행된 선행연구들은 Table 8과 같다.
Table 8.
Similar previous studies aimed at predicting depression
|
Author |
Dataset |
Dependentvariable |
Model |
Diagnostic performance |
|
Seo et al. [19] |
6th Elderly Panel Survey |
Depression or not, Degree of depression |
Decision tree |
Accuracy=0.762 |
|
|
|
Sensitivity=0.723 |
|
|
|
|
Specificity=0.821 |
|
|
|
Random forest |
Accuracy=0.863 |
|
|
|
|
Sensitivity=0.793 |
|
|
|
|
Specificity=0.933 |
|
Kim et al. [20] |
Physical activity information (152 elderly) |
Depression or not |
Support vector machin |
F1-score=0.66 |
|
Kang and Boo [21] |
Senior Research Panel Survey |
Degree of influence on depressive symptoms |
Structural equation |
R2 =0.224 |
|
Su et al. [22] |
China (1,538 elderly) |
Depression or not |
Gradient-boosted decision trees |
Accuracy=0.759 |
|
|
|
Sensitivity=0.429 |
|
|
|
|
Specificity=0.826 |
|
|
|
Random forest |
Accuracy=0.482 |
|
|
|
|
Sensitivity=0.753 |
|
|
|
|
Specificity=0.427 |
|
|
|
Deep neural network |
Accuracy=0.571 |
|
|
|
|
Sensitivity=0.688 |
|
|
|
|
Specificity=0547 |
본 연구에서 제시된 모델의 성능이 만족스러운 수준은 아니지만, 딥러닝을 사용한 다른 모델[ 22]에 비해서는 좋은 성능을 보여주었으며, 해당 모델보다 우수한 성능을 보여준 Seo et al. [ 19]의 연구와 비교해보면, 해당 모델의 성능이 떨어지기는 하지만, 사용된 변수의 수가 30개로, 약 3.53배 더 적은 변수의 수로 패턴을 찾아낸 것을 볼 때, 바쁘게 돌아가는 임상 환경에서는 보다 강점이 있는 것으로 보인다. 그 외 다른 선행연구의 모델[ 20, 21]에 비해서는 우수한 성능을 보여주었다. 해당 연구의 결과를 현장에서 사용하기에는 성능이 부족하지만, 학습에 사용된 데이터에 대하여 우울증에 대한 패턴이 존재하는 것을 확인하였으며 부족하나마 우울증 여부에 대한 대상을 분류하는 모습을 보여주는 것을 볼 수 있다. 본 연구는 딥러닝을 사용하여 우울증을 예측할 수 있는 가능성을 제시하는 연구로 후속 연구에 도움이 될 수 있을 것으로 보인다. 향후, 해당 연구에서 사용한 변수를 제외한 변수를 추가하고, 지금의 딥러닝 모델보다 다양한 층을 추가하여 보다 정확도가 높은 모델을 만들어내면, 지금보다 성능을 향상시킬 수 있을 것으로 보인다. 본 연구는 의료 인력이 부족하고 급하게 돌아가는 임상 환경에 보탬이 되는 것 역시 목적이므로, 독립변수의 수를 단순하게 늘리기보다, 현재의 독립변수보다 적은 수의 변수를 선정하여 접근할 필요성이 있다. 해당 연구에서는 선행연구를 탐색해 얻어낸 주요 변수들을 이용해 딥러닝 모델이 패턴을 찾아낼 수 있는 것을 확인하였으므로, 정형 데이터를 이용하여 우울증 환자를 예측하고자 하는 연구에 대한 지표가 되어 줄 수 있을 것으로 기대된다. 추후 유사한 주제에 대한 데이터를 추가하여, 별도의 시점에 대한 데이터나 다른 기관에서 수집한 데이터를 대상으로 외부 검증을 진행하여 모델의 객관적인 성능을 본 연구보다 명확히 평가할 수 있을 것으로 판단된다.
간단한 모델을 이용해 우울증 환자를 탐지할 수 있다면, 자신이 우울증인 것을 숨기고자 하는 잠재 우울증 환자에 대한 적절한 조치를 통해 고령자의 복지에 도움이 될 것으로 기대한다.
REFERENCES
2. He W, Goodkind D, Kowal P. The aging world: 2015. U.S. census bu-reau, international population reports. Washington, DC: U.S. Govern-ment Publishing Office; 2016.
3. Lee MS, Choi YK, Jung IK, Kwak DI. Epidemiologic study of geriatric depression in an urban area in Korea. Seoul: Korean Association for Geriatric Psychiatry; 2000. p. 154-163. (Korean).
4. National Institute of Mental Health. A fact sheet of statistics on suicide with information on treatments and suicide prevention. Bethesda (MD): National Institute of Mental Health; 2010.
5. Jeon HJ, Lee JY, Lee YM, Hong JP, Won SH, Cho SJ, et al. Lifetime prev-alence and correlates of suicidal ideation, plan, and single and multiple attempts in a Korean nationwide study. J Nerv Ment Dis 2010;198(9):643-646. DOI: 10.1097/NMD.0b013e3181ef3ecf.   6. Hur JS, Yoo SH. Determinants of depression among elderly persons. Ment Soc Work 2002;13:7-35. (Korean).
7. Kim ER. Social capital as a moderator of the relationship between self-rated health and depression among elderly with chronic arthritis. Health Soc Sci 2013;33:59-83. (Korean).
8. Park JK, Lee JR. Analysis of factors affecting the change of depression of Korean adult male and female. Health Soc Sci 2011;29:99-128. (Korean).
9. Ware JE. The assessment of health status: Application of social science to clinical medicine and health policy. New Brunswick: Rutgers University Press; 1989. p. 204-228.
10. Oh YH, Bae HO, Kim YS. A study on physical and mental function affecting self-perceived health of older persons in Korea. J Korea Geron-tol Soc 2006;26(3):461-476. (Korean).
11. Nam YH, Nam JR. A study of the factors affecting the subjective health status of elderly people in Korea. Korean J Fam Welf 2011;16(4):145-162. (Korean).
12. Johnson RJ, Wolinsky FD. The structure of health status among older adults: disease, disability, functional limitation, and perceived health. J Health Soc Behav1993;.34: 105-121.
13. Fehir JS. Self-rated health status, self efficacy, motivation, and selected demographics as determinants of health-promoting life style [dissertation]. The University of Texas at Austin; USA,.1989.
14. Greenberg SA. The geriatric depression scale (GDS). Best Pract Nurs Care Older Adults 2012;4:1-2.
15. Graham JW. Missing data analysis: making it work in the real world. Ann Rev Psychol 2009;60:549-576. DOI: 10.1146/annurev.psych.58. 110405.085530. 16. Ron K. A study of cross-validation and bootsrap for accuracy estimation and model selection Proceedings of the 14th International Joint Conference on Artificial Intelligence;.1995;1137-1145.
17. Cheng HT, Koc L, Harmsen J, Shaked T, Chandra T, Aradhye H, et al. Wide & Deep Learning for recommender systems. DLRS 2016: Proceedings of the 1st Workshop on Deep Learning for Recommender Systems.2016;7-10. DOI: 10.1145/2988450.2988454.
18. Hoffer E, Hubara I, Soudry D. Train longer, generalize better: closing the generalization gap in large batch training of neural networks Proceedings of the 31st International Conference on Neural Information Processing System;.2017;1729-1739.
19. Seo BS, Suh EK, Kim TH. A study on the prediction model of the elderly depression. J Industr Distribution Bus 2020;11(7):29-40. (Korean). 20. Kim JH, An YJ, Kim JH. A predicting depression among senior citi-zens using smart-toy interaction data Proceedings of the Korean Information Science Society Conference;.2020;136-138. (Korean).
21. Kang SK, Boo KC. Predictors of Elderly Depression Using the Anders-en Model. Korean J Gerontoll Soc Welf 2010;49:7-30. (Korean).DOI: 10.21194/kjgsw..49.201009.7. 22. Su D, Zhang X, He K, Chen Y. Use of machine learning approach to predict depression in the elderly in China: a longitudinal study. J Af-fect Disord 2021;282:289-298. DOI: 10.1016/j.jad.2020.12.160.
|
|











